In universitären Instituten und ähnlichen Einrichtungen besteht häufig
das Problem, dass wissenschaftliche Literaturquellen zwar von zahlreichen
Mitarbeitern benötigt, aber von den Einzelnen verwaltet werden. Zur
Verwaltung solcher Zitatbestände wurde eine datenbankgestützte,
WWW-basierte Literaturverwaltung mit ausgefeilter Nutzerstruktur für
einen Linux-Server entwickelt. Die Zugrundelegung einer SQL-Datenbank hat
hierbei den Vorteil, dass sämtliche Verwaltungsoperationen, die nicht über
die standardisierten WWW-Masken ermöglicht werden, über das generische
Datenbankinterface vom Systembetreuer abgewickelt werden können. So ist
gleichzeitig eine effiziente Bedienung für Standardnutzer ohne großen
Einarbeitungsaufwand und bei geringer Fehlerwahrscheinlichkeit mit dem
flexiblen Zugriff auf die Datenbankinhalte durch die Administratoren
kombiniert.
Inhalt
Probleme des Kooperierens: Warum überhaupt eine gemeinsame
Literaturverwaltung?
Der datenbankgestützte Web-Ansatz
Basis der Umsetzung: Linux, CGIHTML, MySQL, C und JavaScript
LILIMAN in Aktion
Oberflächliches
Innereien
Fazit und Ausblick
Viele wissenschaftlich bzw. publizistisch arbeitende Personen haben das Problem, die gelesene Literatur ihres Fachgebietes in verschiedener Hinsicht zu verwalten: einerseits sollen bei einer erneuten Durchsicht des verfügbaren Materials schnell aufgrund von Stichworten oder Anmerkungen spezielle Artikel wiedergefunden werden können, andererseits sollen in einem eigenen Text zitierte Literaturstellen möglichst effektiv in eine Literaturliste übernommen werden können.
Diese Anforderungen stellen bei einzeln arbeitenden Personen keine grundsätzlichen Schwierigkeiten dar. Hierfür gibt es zahlreiche Ansätze für alle möglichen Betriebssysteme und viele jeweilige Textverarbeitungen. Bereits im Falle mehrerer Benutzer auf dem gleichen Rechner ist die Wahl eingeschränkter, doch lassen sich viele der für Einzelarbeiter vorgesehenen Literaturverwaltungssysteme bei kooperativem Arbeitsstil (d.h. insbesondere: gegenseitige Rücksichtnahme hinsichtlich Löschungsoperationen in der Datenbasis, Verändern von Zitierungsschlüsseln u.ä.) weiterverwenden. Ein wirksamer gegenseitiger Schutz vor versehentlichem Verändern ist in der Regel hier schon nicht mehr möglich.
Noch schwieriger gestaltet sich das Befriedigen der Bedürfnisse, wenn Personen einer Arbeitsgruppe unterschiedliche Betriebssysteme mit unterschiedlichen Textverarbeitungen auf unterschiedlichen Rechnern verwenden. Dies ist jedoch in der meist heterogenen Systemlandschaft wissenschaftlicher Institute eher die Regel als die Ausnahme.
In unserem Hause bevorzugen die MS-Windows-/MS-Word-Nutzer üblicherweise eine auf dem Datenbanksystem MS-Access beruhende Literaturverwaltung. Hier herrscht eine eher einfache Tabellenstruktur vor, der keine problemspezifische Verwaltungsfunktionalität zugrunde liegt. Das Einbinden von Zitatstellen erfolgt über Tabellenexporte, die Datenbank selbst ist mangels Schutzmechanismen rein kooperativ angelegt. Durch die geringe problemspezifische Anpassung gestaltet sich beim Einhalten der festgelegten Eingaberegeln die Verwaltung recht einfach.
Die Unix-/Linux-User verwenden hingegen meist LaTeX als Textsatzsystem und zur Zitatverwaltung das zugehörige BibTeX. Dieses bietet eine sehr ausgefeilte, auf die jeweilige Literaturart (Buch, Artikel in Zeitschrift, Handbuch, ...) abgestimmte Verwaltung, wobei die automatische Einbindung der in den eigenen Texten jeweils zitierten Literaturstellen typspezifisch erfolgt: Bei Buchzitaten wird der im Text erzeugte Verweis anders strukturiert als etwa bei Artikelzitaten. Die Bedienung des BibTeX-Systems ist jedoch ziemlich gewöhnungsbedürftig, da es von sich aus keine deutschen Umlaute akzeptiert und eine eher umständliche Klammerhierarchie bei der Zusammenstellung eines gültigen Zitateintrags erfordert. Nichtbeachtung dieser Eingabesystematik wird u.a. mit dem gelegentlichen Abstürzen des Eingabe-Frontends BibView geahndet.
Beide Systeme bieten ungeachtet ihrer spezifischen Vor- und Nachteile keine Gruppenunterstützung im Sinne einer nutzerbezogenen Rechtevergabe an den einzelnen Einträgen. Bei größeren Änderungen an vielen Datensätzen gleichzeitig (z.B. Übergabe einer Zitatsammlung an einen Kollegen) bieten beide Systeme keine gute Unterstützung für effektives Arbeiten.
Für alle Personen ergibt sich beim Erstellen eigener Texte bei der Literatursichtung eine unbestreitbare Aufwandsreduzierung daraus, die bei den Kollegen verfügbare Literatur stichwort- und anmerkungsbezogen durchsehen zu können. Der Konvertierungs- und Aktualisierungsaufwand steigt jedoch sehr schnell sehr stark an, wenn keine wirklich gemeinsame Datenbasis zur Verfügung steht.
Bei der Erstellung einer solchen sind aus klimatischen Erwägungen heraus die unterschiedlichen Mentalitäten der Benutzergruppen zu berücksichtigen: Es ist eine schnelle Eingabemöglichkeit für die Leute sicherzustellen, die nur an einem einfachen Tabellenexport interessiert sind, ohne die problemspezifisch erweiterte Funktionalität für die an Automatismen gewöhnten "Power-User" zu beschneiden. Gleichzeitig sind wirksame Schutzmechanismen für die schon vorhandenen Einträge anderer Eingeber vorzusehen, ohne die möglicherweise nicht ausgenutzten erweiterten Automatismus-Funkionen grundsätzlich auszuschalten.
Die für unsere vollständig vernetzten Rechner sinnvollste gemeinsame Zugangsschnittstelle zu einer Literaturstellenverwaltung, die für beliebige Rechnersysteme erreichbar ist, stellt das Internet dar. Neben der Verfügbarkeit im Institut selbst bietet eine Weblösung zudem den Vorteil, auch Heimarbeiter mit Einwählzugang zum Internet zu unterstützen und einzubinden. Ein solches System war als fertig verfügbares jedoch nicht zu beschaffen, weshalb wir uns letztlich zu einer Eigenprogrammierung entschlossen: Das war die Geburtsstunde unseres LILIMAN-Systems.
Es basiert auf der kleinen, aber schnellen relationalen Datenbank MySQL, die auf einem Linux-Rechner betrieben wird. Die hierbei verwalteten Eintragsfelder pro Literaturstelle (Autor, Titel, Herausgeber, Stichworte, ...) sind stark an das BibTeX-System angelehnt, erweitern und straffen dieses jedoch hinsichtlich einiger Punkte, wie weiter unten noch ausführlich dargestellt wird.
Die Entwicklung eines solchen Literaturverwaltungssystems in seiner ganzen Komplexität stellt nun nicht gerade die Hauptaufgabe eines Thermodynamik-Instituts dar. Daher wurden im Sinne einer Aufwandsminimierung zunächst nur die Funktionen webmäßig verfügbar gemacht, die regelmäßig von allen Nutzern für ihre tägliche Arbeit nachgefragt werden. Weitergehende Funktionen stehen derzeit nur dem Systemverwalter über die SQL-Schnittstelle zur Verfügung, werden aber nach und nach per Web organisiert. Die SQL-Schnittstelle erlaubt insbesondere auch, Fremddaten aus anderen Systemen nach relativ geringer Zwischenbearbeitung einzuspielen. So konnten schon bestehende Datenbestände aus Access- und BibTeX-Datenbanken übernommen werden.
Zu Linux als extrem stabilen Serverbetriebssystem braucht hier wohl kaum etwas gesagt zu werden. Wir haben jedenfalls bereits über Jahre hinweg durchweg positive Erfahrungen gemacht und daher ein auf der SuSE-5.3-Distribution aufbauendes Linux als Basis für das letztlich als Multi-User-/Multitasking-System ausgelegte Literaturverwaltungssystem verwendet.
Die Wahl des zugrundeliegenden Datenbankteils musste verschiedenen Anforderungen genügen: einerseits soll die Datenbank schnelle Antwortzeiten erlauben. Andererseits soll auf dem Rechner, der die Datenbank verwaltet, auch noch normal gearbeitet werden können. Wir wählten daher das MySQL-System aus, das zwar hinsichtlich Funktionalität bei verketteten Tabellen einige Wünsche offen lässt, dafür jedoch laut Performance-Vergleichsstatistiken seine vorhandenen Funktionen ausgesprochen schnell ausführt. Da für die Literaturverwaltung zumindest zunächst keine allzu komplexen Querbezüge zu verwalten sind, erschien uns diese Datenbank als die geeignetste.
Während viele Web-Programmierer auf Perl als die CGI-Sprache der Wahl setzen, gingen wir mit der Verwendung von C einen anderen Weg: Abgesehen davon, dass der Autor traditionell diese Sprache bevorzugt und nach wenigen Tagen Abstinenz einen Perl-Code erst wieder mühsam nachvollziehen muss, ist die interpretative Abarbeitung der CGI-Skripte durchaus zeitraubend. Im Maschinencode unmittelbar lauffähige, kleine CGI-Programme von typisch 50 kB Größe belasten hingegen den Server weniger und garantieren kleinstmögliche Antwortzeiten.
Der Einsatz reinen C-Codes für den Aufbau von CGI-Interaktionen hätte die Benutzerschnittstelle doch arg eingeschränkt: Sobald eine WWW-Seite für den Nutzer sichtbar geworden ist, existiert schließlich das erzeugende CGI-Programm nicht mehr und kann daher nicht mehr auf Benutzerinteraktionen reagieren. Mit dem Übermitteln irgendwelcher Eingaben würde aber wiederum das nächste CGI angeworfen und müsste eine neue Webseite aufbauen, um das nachgefragte Resultat zu präsentieren. Dieses rein impulsartige Interaktionsschema wird durch Verwenden von JavaScript-Elementen, die eine begrenzte Anzahl von unmittelbaren Kontrollen und Darstellung von Zusatzinformation in der geladenen Seite erlauben, zumindest ein wenig aufgeweicht.
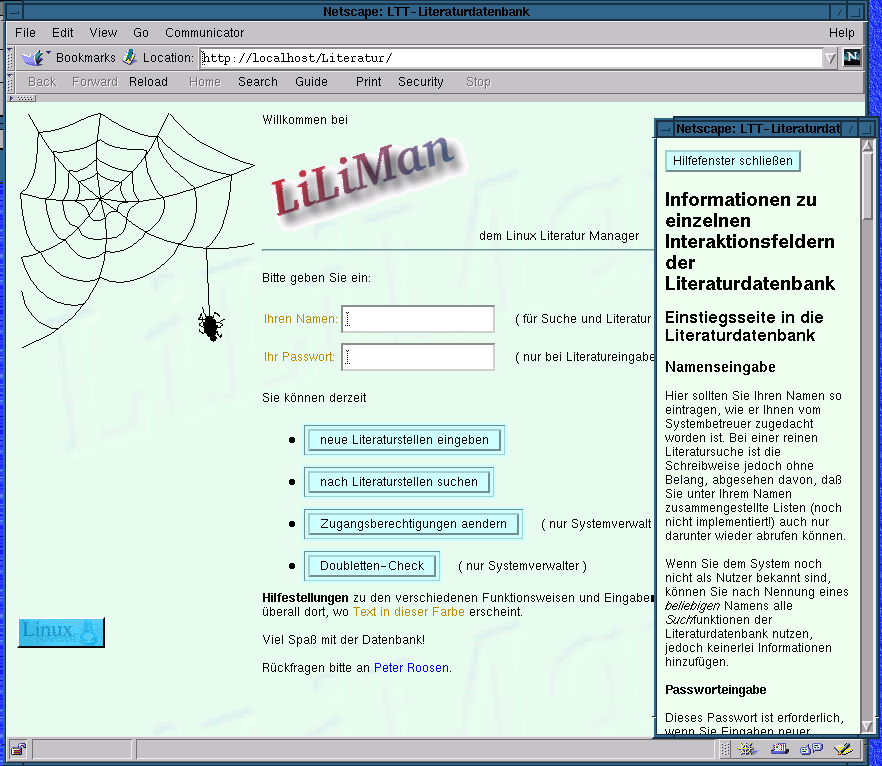
Das LILIMAN-System ist voll dynamisch aufgebaut. Es existieren daher derzeit genau zwei statische HTML-Seiten im gesamten System: Die Anmelde-/Einstiegsseite und eine Hilfestellungsseite zu den Interaktionsmöglichkeiten (Bild 1) mit dem System. Letztere enthält eine Vielzahl von Einsprungstellen, die von den farblich markierten Hilfetags in den Funktionsseiten gezielt angesprungen werden und so eine kontextsensitive Hilfestellung bieten.
|
| Bild 1: Statische Einsprungseite und Hilfetext |
Von der Einsprungseite aus lassen sich direkt die beiden Grundfunktionen "Literaturstellen einfügen" und "Literaturstellen suchen" anwählen, nachdem man Namen und Passwort eingegeben hat. Die farbliche Unterlegung der Eingabefeldbezeichnungen zeigt dem Benutzer, dass bereits hier erste Einsprungstellen in den Hilfetext vorhanden sind, der nach dem entsprechenden Klick wie in Bild 1 als kleines separates Fenster erscheint.
Beliebige Benutzer dürfen derzeit die reinen Suchfunktionen des Systems nutzen. Hierfür ist nur die Eingabe eines (beliebigen) Namens erforderlich. Im weiteren Verlauf der Literatursystemnutzung gibt es jedoch auch für schon existierende Verweise zusätzliche Eingabemöglichkeiten, die nur registrierten Benutzern des Systems offenstehen. Daher ist es auch direkt zu Anfang schon ratsam, sich mit richtigem Namen und Passwort anzumelden.
Zur Eingabe des Suchwunsches wird eine standardisierte Maske (Bild 2) mit verschiedenen Eingabefeldern präsentiert. Da der Benutzer ja nicht weiß, welche Stichworte dem System schon bekannt sind, kann er sich ein Hilfefenster mit einer Liste anzeigen lassen, aus dem einzelne Einträge per Mausklick in das entsprechende Suchfeld der Maske übernommen werden.
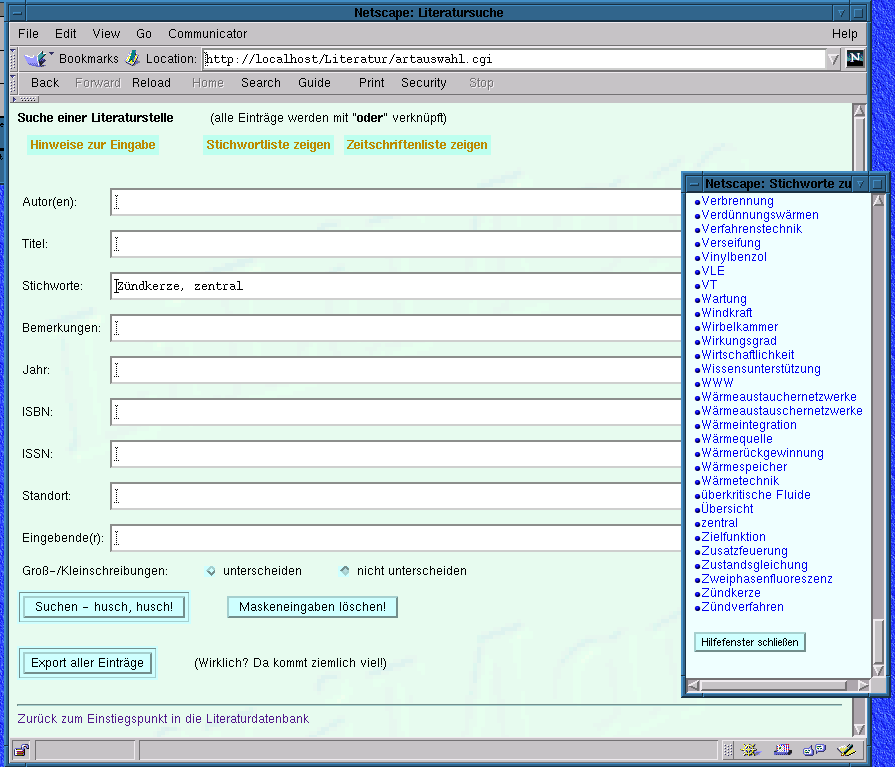 |
| Bild 2: Suchmaske für Literaturzitate |
Die kommagetrennt eingegebenen Begriffe werden grundsätzlich als ODER-Verknüpfung gesucht. Mit Hilfe eines Radio-Buttons lässt sich schließlich festlegen, ob die Groß-/Kleinschreibung bei den Eingaben berücksichtigt werden soll.
Nach Abschicken des Suchauftrags wird wiederum ein CGI-Programm aufgerufen, das über Ansprechen des Datenbank-Interfaces die passenden Einträge ermittelt und in einer tabellarischen Übersicht präsentiert, in der nur einige der verwalteten Eintragsfelder dargestellt werden (Bild 3).
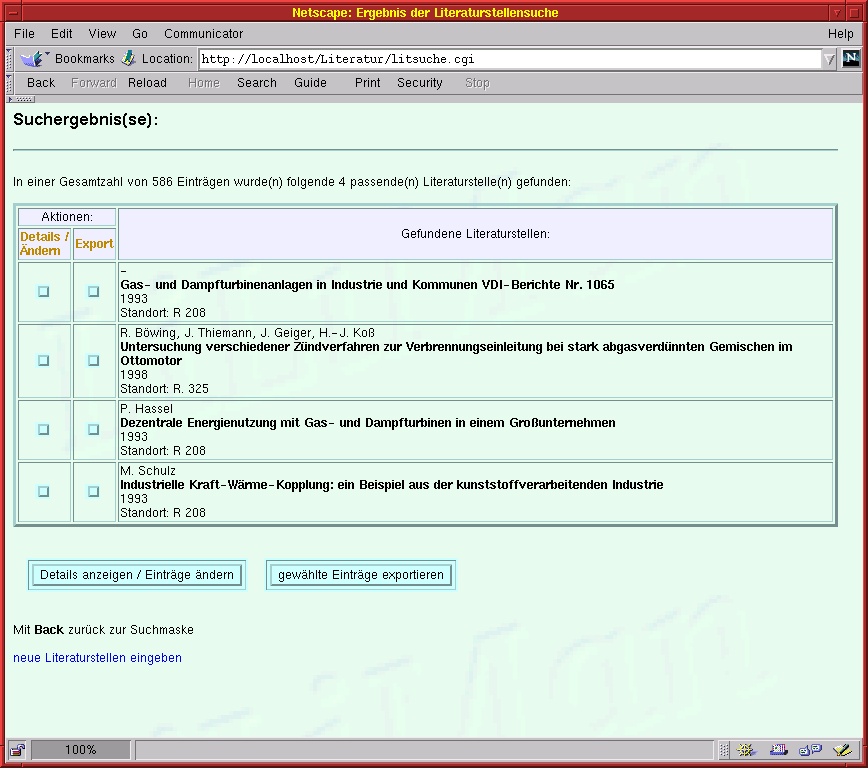 |
| Bild 3: Suchergebnisse als tabellarische Übersicht |
Hier können nun einzelne Fundstellen für detailliertere Ausgaben oder den Export in die eigene Textverarbeitung markiert werden.
Werden einzelne der gefundenen Einträge zum Export markiert, und die entsprechende Funktion unterhalb der Tabelle angewählt, werden vom System zwei Exportdateien erstellt: eine BibTeX-Datei und eine einfache ASCII-Exporttabelle gemäß den Wünschen unserer MS-Word-Fraktion. (Weitere Exportformate können bei Bedarf in dem entsprechenden CGI-Programm recht einfach implementiert werden, da dort die vollständigen Eintragsdaten für jedes zu exportierende Zitat vorliegen und so nur die jeweilige Formatierung eingehalten werden muss.) Diese Dateien werden über eine ebenfalls vom CGI-Programm generierte Webseite zum Download angeboten. Über einen Cron-Job werden schließlich Exportdateien, die älter als einen Tag sind, wieder aus dem Download-Verzeichnis entfernt. So bleibt den jeweiligen Auftraggebern genügend Zeit, das gewünschte Material abzurufen.
Wählt man einen oder mehrere Einträge an, um sich weitere Eintragsdetails zeigen zu lassen, werden für diese vorliegenden Informationen in tabellarischer Form zusammengestellt. Neben dieser Listung besteht für jeden Eintrag die Möglichkeit, Teilinformationen zu ändern und zu ergänzen.
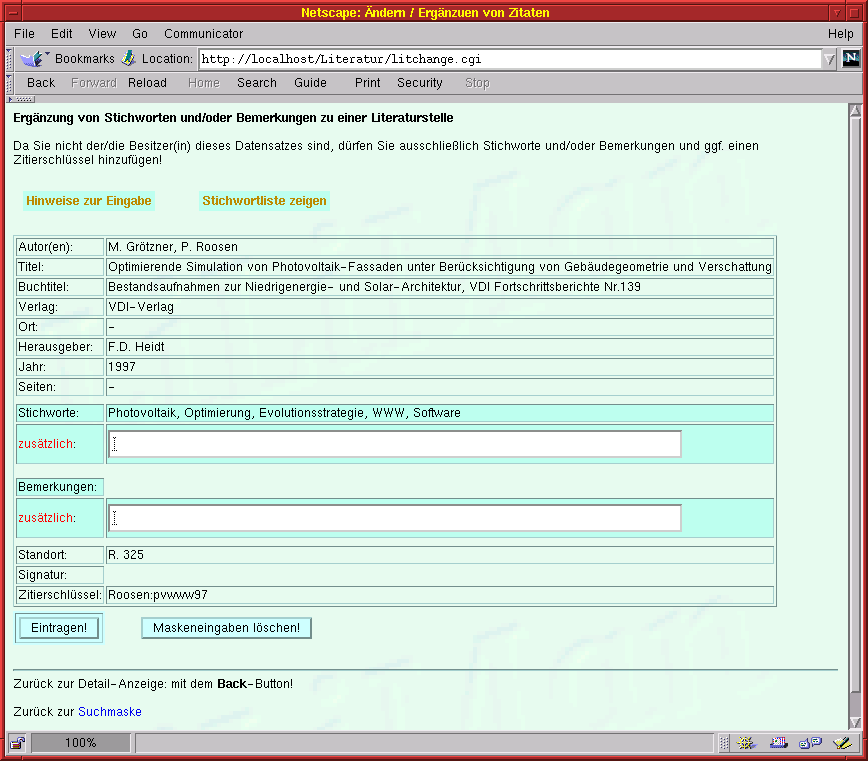 |
| Bild 4: Änderung existierender Einträge durch Nicht-Besitzer |
Hier kommt nun das vierschichtige Benutzerrechtesystem zum Tragen:
Nicht eingetragene Benutzer dürfen keinerlei Änderungen an den Daten vornehmen.
Der "Besitzer" eines Datensatzes, also die Person, die als ursprünglicher Eingeber vermerkt ist, darf alle Eintragsfelder verändern und sogar den Eintrag (durch vollständiges Löschen sämtlicher Eintragsfelder) wieder aus der Datenbank herausnehmen.
Natürlich gibt es wie in Orwells Animal Farm immer Individuen, die etwas gleicher sind: die Systembetreuer. Sie dürfen unabhängig von den Besitzrechten an einem Datensatz ebenfalls alle Daten abändern oder löschen.
Eingetragene Benutzer des Systems, die jedoch nicht Erzeuger des gerade interessierenden Datensatzes sind, dürfen immerhin Stichworte und Anmerkungen zu den schon existierenden hinzufügen, nicht jedoch die der anderen Nutzer entfernen (Bild 4). Sämtliche in diese Felder eingegebenen Informationen sind für alle Abrufer sichtbar - man sollte sich also überlegen, welche Anmerkungen man eingibt!
Als ein grundsätzlich optionales Eintragsfeld existiert bei allen Literaturarten ein Zitierschlüssel, den jedoch nur die BibTeX-Fraktion der Nutzer für eine automatische Generierung einer Literaturliste in einem eigenen Dokument einsetzen kann. Da diese jedoch auch Einträge der anderen Kollegen für den Automatismus verwenden möchten, besteht für Zitate, die ohne Zitierschlüssel eingegeben wurden, für alle zunächst die Möglichkeit, einen solchen nachzutragen. Nach der Eingabe geht er jedoch in den "Besitz" des ursprünglichen Eingebers über und kann fortan nur von diesem oder einem Systemverwalter geändert werden.
Auch wenn für ein Zitat kein expliziter Schlüssel existiert, wird ein Standardschlüssel der Form Zitatxx im BibTeX-Export generiert, so dass der Mehraufwand des eigenen Schlüsselnachtrags nicht grundsätzlich erforderlich ist.
... womit wir eigentlich auch schon mitten in den Eingabemöglichkeiten wären.
Doch fangen wir hierbei noch einmal von vorne an:
Wählt man nach dem Login die Eingabe neuer Literaturstellen an, erhält man zunächst eine Liste verschiedener Literaturformate. Schließlich macht es einen Unterschied, ob man einen Artikel einer Zeitschrift, ein Buch oder eine Webseite referenzieren und beschreiben möchte.
Je nach Auswahl der Literaturform wird eine darauf zugeschnittene Eingabemaske aufgebaut, die neben erzwungenen auch optionale Felder enthält (Bild 5). Die Auswahl der jeweiligen Felder ist hier stark an die des BibTeX-Systems angelehnt, in das ja einiges an bibliographischen Kenntnissen eingeflossen ist. Einige vom BibTeX nicht unterstützte Literaturformen (Studienarbeiten, Webseiten) wurden durch Hinzunahme entsprechender Zusatzfelder implementiert, wohingegen inhaltlich praktisch gleiche Einträge (Organisation, Institution) verschiedener BibTeX-Literaturarten auf das gleiche Datenbankfeld abgebildet werden. Auch die Einordnung einiger Eintragsfelder hinsichtlich ihrer Zwanghaftigkeit wurde unserer Institutspraxis angepasst.
Ungehorsam des Eingebers in Form eines nicht vollständigen Ausfüllens der Zwangsfelder wird mit Annahmeverweigerung bestraft! Aber da der Autor auch nicht zu hart mit den Kollegen sein wollte, werden die Zwangseinträge (zumindest noch) nicht auf Sinnhaftigkeit überprüft, so dass notfalls ein einfacher Strich ausreicht, wenn wirklich einmal die eigentlich notwenige Information nicht verfügbar sein sollte.
Doch was gibt man nun bei Stichworten und Zeitschriftenbezeichnungen ein? Werden zuviele unterschiedliche Stichworte verwendet, verlieren diese beim Suchen ihre Funktion; werden Zeitschriften von Zitat zu Zitat unterschiedlich benannt, ergibt das zumindest beim Einbinden in eigene Texte unschöne Literaturlisten. Hier war ein Kompromiss zu schaffen zwischen Unterstützung bei der Auswahl existierender Bezeichnungen und Stichworte und der Möglichkeit, wirklich neue Einträge einzubringen.
 |
| Bild 5: Eintragsmaske für ein Literaturzitat mit Hilfsfenstern zur Stichwort- und Journalauswahl |
Die hierbei beste Methode, befand der Autor, war die Auflistung entsprechender Informationen in jeweils separaten Fenstern, aus denen die teilweise komplexen Wörter oder Bezeichnungen vertippfrei durch einfaches Anklicken in das Neueintragsformular übernommen werden können. Die jeweiligen Listen werden über die Hilfefunktion in separate Listenfenster eingeblendet. Die Tippfaulheit der meisten Nutzer führt wegen der einfachen Übernahmemöglichkeit nun dazu, dass immer seltener neue Stichworte bzw. Zeitschriftenbezeichnungen eingetragen werden.
Jede (Neu-)Eingabe in die Stichwort- und Zeitschrift-Felder der Eingabemaske wird vom eintragenden CGI-Programm mit den schon existierenden Bezeichnungen abgeglichen. Ist ein entsprechender Eintrag noch nicht vorhanden, wird er in die Datenbank eingefügt und steht ab nun den Nachfolgenden zur Auswahl zur Verfügung.
Damit werden alle bei der regelmäßigen Arbeit mit Literaturzitaten erforderlichen Funktionen über das Web-Interface bereitgestellt.
Wie schon erwähnt, liegt LILIMAN die Datenbank MySQL zugrunde. Entsprechend wird die Kohärenz des ganzen Systems hauptsächlich durch eine Reihe von Hilfstabellen gesichert, die neben der eigentlichen Literaturtabelle mitverwaltet werden. Hier werden beispielsweise die Zwangsfelder und optionalen Felder den verschiedenen Literaturarten zugeordnet, die Benutzerrechte abgelegt und die Bezeichnung der Eintragszeilen von einer internen in eine explizite für die Maske übersetzt. Auch die Stichworte und Zeitschriftenbezeichnungen werden in separaten Tabellen verwaltet und können daher getrennt nachbearbeitet werden.
Durch diese weitestgehend datenbankgestützte Zuordnung der internen Eigenschaften kann der Systemverwalter die Eigenschaften des Systems, z.B. die Reihenfolge der Eintragsfelder in den Eingabemasken oder die Festlegung von Einträgen als erzwungen/optional, sehr einfach durch SQL-Kommandos verändern und den örtlichen Gepflogenheiten anpassen.
Auch die Nutzerverwaltung wird über die Datenbank verwaltet. Daher ist es ohne Probleme möglich, Administratoren, Datensatzbesitzer, Schreibberechtigte und unterpriviligierte Nur-Leser nach Belieben ineinander umzuwandeln. Der vollständige Ausschluss der Öffentlichkeit, den wir derzeit nicht einsetzen, wird hierbei jedoch nur über das Passwort-System des Webservers ermöglicht.
Bisher sind keine Ausfälle des Literaturverwaltungssystems aufgetreten, obwohl die Weiterentwicklung sozusagen am offenen Herzen, also mit der in Benutzung befindlichen Datenbank, vorangeht. CGI-systembedingt bleiben Defizite bei der Benutzerinteraktion, die nur durch zusätzliche Elemente (Java Applets?) eliminiert werden könnten. (Interessierte Mitentwickler zur gemeinschaftlichen Weiterentwicklung sind hier herzlich willkommen!)
Die getroffene Wahl der Entwicklungskomponenten hat sich durchaus bewährt, wobei der JavaScript-Anteil in zukünftigen Versionen mit Sicherheit noch steigen wird. Obwohl der grundsätzliche Ansatz der durch Nicht-Besitzer ergänzbaren Einträge funktioniert, kam bei den Nutzern doch der Wunsch nach weiterer benutzerspezifischer Verwaltung auf. Dies wird in Zukunft mit einer geänderten Verwaltung der multiplen Felder (Standorte, Signaturen, Stichworte, Bemerkungen, ...) realisiert werden.
Derzeit werden bereits einige hundert Einträge verwaltet, und testweise wurden bereits aus (noch abzugleichenden) BibTeX-Zitatbeständen noch einige weitere hundert eingebunden. Trotzdem bewegen sich die Antwortzeiten bei Suchen und Exporten auch bei einem mit weiteren Aufgaben parallel belasteten Server im Sekundenbereich. Der interaktive Betrieb auf dieser Maschine wird dabei nicht spürbar beeinträchtigt. Man muss dabei berücksichtigen, dass die ca. 50 sporadischen Nutzer jeweils nur sehr kurzfristige Lastspitzen bei Datenbankzugriffen erzeugen; das dürfte jedoch bei dieser Aufgabenstellung gerade der Normalfall sein.
LILIMAN ist "work in progress": Es verbleiben noch einige Ecken und Kanten, die im Laufe der Zeit noch geglättet werden müssen, um das Arbeiten mit dem System so angenehm wie möglich zu machen. Nach und nach werden weitere Funktionen über die Web-Oberfläche zugänglich gemacht, so dass als Endziel ein (fast) vollständig über die graphische Schnittstelle steuerbares Gesamtsystem erreicht werden dürfte.
Bei der Kooperation vieler Personen lassen sich versehentliche Fehleingaben, insbesondere Doppeleingaben, nicht vermeiden. Hierbei gibt es auch bei grundsätzlich gleichen Daten leichte Unterschiede in der Eingabe, die das Erkennen solcher Doubletten erschweren. Daher wird derzeit ein differenziertes Doubletten-Suchsystem implementiert, das den gesamten Datenfundus regelmäßig auf der Basis unterschiedlicher Wichtungen von Autoren-, Titel-, Jahresangaben usw. durchsucht und bei Verdacht auf das Vorliegen eines doppelten Eintrags eine Warnmitteilung an einen oder mehrere Systembetreuer verschickt. Bereits konzipiert ist eine dazu passende Weboberfläche, die ebenfalls datenbankgestützt Unterscheidungen zwischen vermuteten (gelb), erkannten, aber noch nicht ausgemerzten (rot), und definitiv als Nicht-Doubletten erkannten Einträgen (blau) erlaubt (Bild 6).
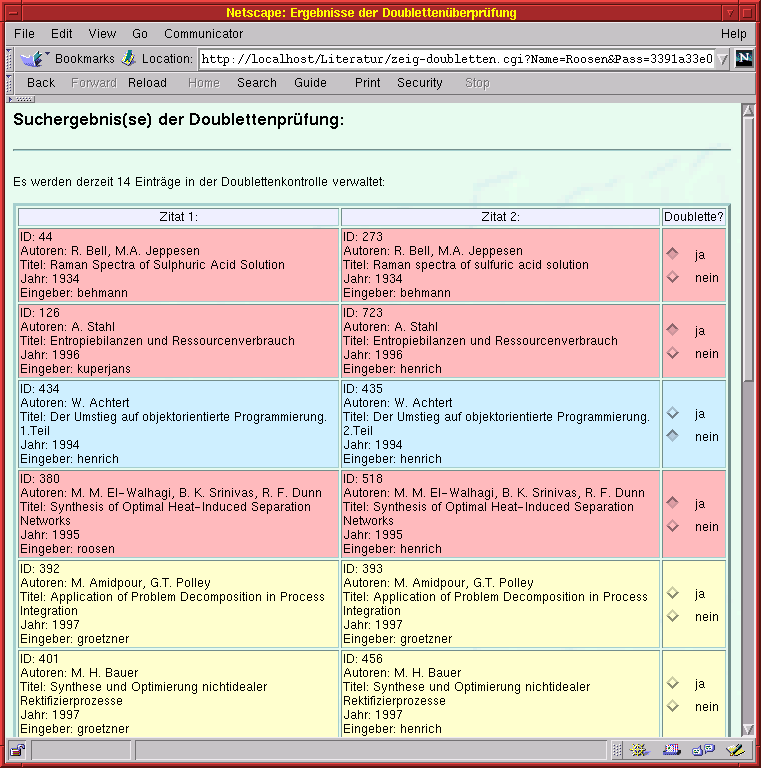 |
| Bild 6: Doubletten-Kontrollanzeige |
Insgesamt soll durch Kombination von Interaktivität und autonomer Intelligenz so ein Verwaltungssystem entstehen, das sowohl hinsichtlich Funktionalität als auch Wartbarkeit bestmöglich auf die Erfordernisse des wissenschaftlichen Zitat-Alltags abgestimmt ist.
... und falls jemand Interesse an LILIMAN in Aktion hat: Hier ist eine Schnupperversion!