
Ein kompakter Cluster aus acht Rechenknoten in einem Servertower(6), einem Miditower(2) und dem Masterrechner.
Parallelrechner, die ausschließlich aus Standardkomponenten bestehen (a.k.a
"Beowulf"), haben in den letzten Jahren
viel Aufsehen erregt. Der Vortrag soll ausgehend von der geschichtlichen
Entwicklung im wesentlichen folgende Fragen beantworten:
Inhalt
Historie
Quickstart
Hardware
Software
Wie aufwendig ist die Parallelisierung von Programmen?
Trivial: "hello world"
Parallele Compilierung
Parallele Quantenchemie I
Raytracing
Parallele Quantenchemie II
Wie leistungsfähig ist ein Beowulf?
Raytracing
Paralleles Compilieren
Moleküleigenschaften
Alternative Vernetzung und Neuere Entwicklungen
Beowulf und Hochverfügbarkeit
Anwendungsbeispiele aus der Praxis
Weiterführende Informationen
Seit Anfang der 80er-Jahre begannen immer mehr Unix-basierte RISC-Workstations Abteilungen und Institute zu bevölkern. Ihre zunehmende Leistungsfähigkeit führte zur Idee sie zu clustern und nachts und am Wochenende, wenn sie nicht interaktiv benutzt wurden, für rechenintensive Anwendungen zu nutzen. Das NoW-Konzept (Network of Workstations) war geboren. Nächster Schritt war die Nutzung solcher Cluster so zu vereinfachen, dass sie dem Anwender wie ein einziger virtueller Parallelrechner erscheinen. Das geschieht mit Hilfe des Message-Passing-Programmierparadigma, das eine relativ leicht zu bedienende Kommunikation zwischen Prozessen auf verschiedenen Rechnern erlaubt. Erster prominenter Vertreter war die Message-Passing-Bibliothek PVM. Nachdem nun Anfang der 90er-Jahre parallele Programmierung auf vernetzten Workstations möglich war, machte der Erfolg PC-basierter freier Unix-Varianten diese Softwareinfrastruktur auch für die Intel-Plattform verfügbar. Das günstige Preis/Leistungsverhältnis moderner PC- und Netzwerkhardware führte zu der Idee, auf die Möglichkeit interaktiv an Rechnerknoten arbeiten zu können zu verzichten und komplette Parallelrechner aus PC-Hardware zu bauen. Der erste bekanntere Rechner dieser Kategorie war der 486er-Cluster "Beowulf" der NASA (Thomas Sterling u. Donald Becker, 1994). Mittlerweile hat sich die Bezeichnung Beowulf zur Beschreibung dieser Rechnerklasse eingebürgert und erste Rechner dieses Typs erscheinen in der TOP500-Liste der schnellsten Rechner der Welt.
Beowulf ist das älteste englischsprachige Heldenepos. Aus unerfindlichen Gründen nennen viele Administratoren ihre Rechner nach Figuren in bekannten Sagen oder Erzählungen. Genau das war bei der NASA geschehen. Ein Rechner, der den Namen beowulf hatte, ist mehr oder weniger zufällig Konsolenrechner des ersten NASA-Cluster geworden. Es gibt also keinen irgendwie gearteten Zusammenhang zwischen dem Inhalt des Epos und den Eigenschaften eines Clusters.
Aussehen und Hardware von Beowulf-Clustern kann recht unterschiedlich sein. Meist bestehen sie aus 4 bis 64 Rechenknoten und einem einzelnen Masterrechner. Die einzelnen Rechenknoten sind meist PCs in Minitower-Gehäusen, gestapelt in Stahlregalen. Wer mehr Geld ausgeben und den "IKEA-Touch" verhindern will, kann mittlerweile auch fertige Lösungen in 19''-Industriestandard-Gehäusen mit Temperaturüberwachung und zusätzlichen Features kaufen. Hier gibt es zwei Abbildungen, wie unterschiedlich Cluster aussehen können:
Ein kompakter Cluster aus acht Rechenknoten in einem Servertower(6), einem
Miditower(2) und dem Masterrechner.

Der erste Beowulf, der in den TOP500 war (70 Alpha/533MHz Rechner).
Was braucht man nun um sich einen ersten Überblick über die Möglichkeiten und Grenzen von Beowulf-Clustern zu verschaffen? Wie die beiden folgenden Abschnitte zeigen, recht wenig. Ein erster sinnvoll dimensionierter Beowulf lässt sich heute einschließlich Netzwerk zu einem Preis zusammenbauen, für den man vor einigen Jahren nicht einmal einen vernünftigen PC bekam.
Im Folgenden wird davon ausgegangen, dass ein Cluster zu Testzwecken gebaut werden soll. D.h. ein kostengünstiger Prototyp, der sich nicht zu weit vom echten Produktionscluster unterscheiden soll. Ein praktischer Vorschlag könnte z.B. aus folgender Hardware bestehen:
Soll das Zielsystem hauptsächlich Integer-Operation durchführen, bieten sich Prozessoren der Firma AMD an, bei FPU-intensiven Aufgaben bieten sich Pentium-II-/Pentium-III-/Celeron-Prozessoren von Intel an. Die Verwendung gleicher Prozessoren ist nicht zwingend erforderlich, erlaubt aber wesentlich einfacher Rückschlüsse auf die Skalierbarkeit. Unter Skalierbarkeit versteht man die Ausführungsbeschleunigung bei Erhöhung der Rechenknotenzahl einer parallelen Anwendung. Einen PC verwendet man als Masterrechner und stattet ihn mit Monitor, Grafikkarte, Tastatur, Maus und einer größeren Festplatte aus. Bei den drei Rechenknoten kann man auf die Grafikkarten etc. verzichten und es reichen meist kleinere Festplatten. In der Regel ist es sinnvoll das System so zu konfigurieren, dass die Rechenknoten das /usr, /opt, /home etc. Verzeichnis des Masterrechners via NFS mounten. Genauere Informationen, wie man vorgeht, geben die mittlerweile zahlreichen HOWTOs:
Natürlich kann man den hier vorgeschlagenen Cluster noch in viele Richtungen modifizieren, z.B.:
Die Programmierung von Beowulf-Clustern erfolgt in den meisten Fällen durch die Nutzung von Message-Passing-Bibliotheken. Die älteste der wichtigen Bibliotheken ist das schon erwähnte PVM (Parallel Virtual Machine). In der Nachfolge bildete sich der Standard MPI (Message Passing Interface). Diesem Standard folgen die MPI-Implementierungen LAM und MPICH. Einen (etwas veralteten) Überblick über Gemeinsamkeiten und Unterschiede zwischen PVM und MPI findet man hier. Ich werde mich im Folgenden auf PVM beschränken. PVM lässt sich auf nahezu allen Unix-Plattformen nach Setzen der Umgebungsvariable PVM_ROOT auf das für PVM benutzte Verzeichnis durch make und make install übersetzen und installieren.
Die Nutzung von Message-Passing-Bibliotheken gestaltet sich, auch wenn es auf den ersten Blick vielleicht nicht so aussieht, relativ einfach.
Hier ist ein elementares Master/Slave-Beispiel. Beim Master/Slave-Programmierparadigma wird ein Master-Prozess wie ein normales Programm gestartet, und dieser Prozess startet selbständig Slave-Prozesse auf den Rechenknoten, die Teilaufgaben lösen und an den Master-Prozess zurücksenden. Das Master-Programm hello.c startet auf den Rechnern der virtuellen Maschine das Programm hello_other und wartet darauf, dass es von einem Rechenknoten einen String geschickt bekommt. Dieser String wird dann ausgegeben.
#include <stdio.h>
#include "pvm3.h"
main()
{
int cc, tid;
char buf[100];
printf("i'm t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "", 1, &tid);
if (cc == 1) {
cc = pvm_recv(-1, -1);
pvm_bufinfo(cc, (int*)0, (int*)0, &tid);
pvm_upkstr(buf);
printf("from t%x: %s\n", tid, buf);
} else
printf("can't start hello_other\n");
pvm_exit();
exit(0);
}
Die Slave-Variante (hello_other.c) liefert den String hello, world from an den Master-Prozess.
#include "pvm3.h"
main()
{
int ptid;
char buf[100];
ptid = pvm_parent();
strcpy(buf, "hello, world from ");
gethostname(buf + strlen(buf), 64);
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, 1);
pvm_exit();
exit(0);
}
Übersetzt werden beide Programme z.B. so:
cc -I$PVM_ROOT/include -L$PVM_ROOT/lib/LINUX hello.c -lpvm3 -o hello cc -I$PVM_ROOT/include -L$PVM_ROOT/lib/LINUX hello_other.c -lpvm3 -o hello_other
Die PVM-Bibliothek besteht aus mehreren Dutzend Unterroutinen, die alle den Präfix pvm_ führen. Die zentralen Routinen sind aber pvm_send und pvm_recv, die genau das machen, was ihre Namen nahelegen. Vereinfacht gesagt besteht die Parallelisierung eines Programmes darin, Master- und Slave-Programme so zu synchronisieren, das das Master-Programm dem Slave-Programm zuerst alle zur Lösung des Teilproblems notwendigen Daten schickt und anschließend die Ergebnisses zurücknimmt. Wer weiß, was eine Matrizenmultiplikation ist, sollte versuchen dieses Problem mit Hilfe von PVM oder MPI zu parallelisieren. Sollte das nach einigen Stunden des Rumprobierens erfolgreich gelungen sein, hat man Wesentliches über parallele Programmierung gelernt.
Wichtig ist noch zu erwähnen, dass weder PVM noch MPI Root-Rechte bei Installation oder Nutzung voraussetzen. Wer also Zugang zu einem Rechnerpool hat, kann diesen via PVM/MPI in einen leistungsstarken Parallelrechner verwandeln.
Eigentlich ist nach der Installation von PVM bzw. MPI der Parallelrechner komplett. Es gibt aber einige Punkte, die beim Einrichten eines Beowulfs zusätzlich beachtet werden sollten:
Das obige Beispiel des parallelen Hello-World-Programmes zeigt, dass die Nutzung von Message-Passing-Bibliotheken nicht ganz trivial ist. Ein besonderes zusätzliches Problem bei der parallelen Softwareentwicklung ist das Fehlen freier Debugger. Folgender Erfahrungssatz gibt einen Hinweis über die bei der Parallelisierung eines Programmes zu erwartenden Aufwand:
10% des Programmcodes erzeugen 90% der Laufzeit.
Man muss sich also bei der Parallelisierung eines (hinreichend modularen!) Programmes mit nur 10% des Code auseinandersetzen. Geht man nun davon aus, dass im Laufe der Parallelisierung ca. 30-50% dieses zehnprozentigen Codeanteils neu geschrieben werden muss, und der Codeumfang dieses Anteils um ca. 30-50% steigt, so folgt, dass die parallele Version eines Programmes nur ca. 5% größer als die serielle Variante ist und ca. 6-10% des Gesamtcode neu ist. Diese Zahlen sind natürlich nur grobe Richtlinien und können wesentlich über- aber auch unterschritten werden. Die folgenden vier Beispiele zeigen deutlich,
Die parallelisierte Version des Hello-World-Programmes erfordert eine Vervielfachung des Code und relativ viele Kommunikationsbefehle. Dies ist auf die geringe Größe der seriellen Variante zurückzuführen.
| hello.c | pvm_hello.c | |
| Codezeilen | 3 | 30 (+1000.0%) |
| Kommunikationsbefehle | 9 |
Das verwendete PVMMAKE verteilt die einzelnen Übersetzungen auf die Rechenknoten. Diese parallelisierte Version einer make-Variante erforderte eine erhebliche Vergrößerung des Code und relativ viele Kommunikationsbefehle:
| MAKE | PVMMAKE | |
| Codezeilen | 1765 | 2767 (+57.0%) |
| Kommunikationsbefehle | 136 |
Das Programm HFSCF berechnet Energien und Eigenschaften von Molekülen. PVMHFSCF parallelisiert die notwendigen Integralberechnungen, PVMHFSCF2 parallelisiert zusätzlich noch den bei der Optimierung anfallenden Festplatten-I/O. Es zeigt sich, dass sowohl die Parallelisierung der Integralberechnungen als auch die des Festplatten-I/O mit vertretbarem Aufwand möglich waren.
| HFSCF | PVMHFSCF | PVMHFSCF2 | |
| Codezeilen | 2539 | 2635 (+3.8%) | 2814 (+10.8%) |
| Kommunikationsbefehle | 21 | 35 |
Das bekannte Programm POVRAY3 ist ein sog. Raytracer, der photorealistische Szenen aus einer Szenenbeschreibung erzeugt. Raytracing ist im Allgemeinen sehr rechenintensiv und lässt sich relativ leicht parallelisieren (PVMPOV3.1 bzw. FLY3). Es zeigt sich, dass die vorhandenen Patches zur Parallelisierung den Codeumfang nur unerheblich vergrößern.
| POVRAY3 | PVMPOV3 | FLY3 | |
| Codezeilen | 112185 | 113722 (+1.5%) | 115818 (+3.2%) |
| Kommunikationsbefehle | 121 | 85 |
GAMESS ist ein mächtiges quantenchemisches Allroundprogramm. Signifikante Beschleunigung wurde mit nur 222 zusätzlichen Codezeilen erreicht.
| GAMESS | GAMESS+MPI | |
| codezeilen | 265397 | 265619 (+0.0001%) |
| Kommunikationsbefehle | 15 |
Viele Programmpakete verwenden Standard-Unterroutinen zur Lösung numerischer Teilprobleme. Es gibt für einige dieser Standardbibliotheken auch schon parallele Äquivalente. Dies erleichtert natürlich die Parallelisierung eigener Programme, die diese Standardbibliotheken verwenden, erheblich. Für das beliebte LINPACK/EISPACK/LAPACK gibt es die äquivalente parallele Implementierung ScaLAPACK.
Das Benchmarking von Beowulf-Clustern ist noch deutlich schwieriger als bei Einzelprozessor-Rechnern. Die Faustregel lautet:
"Alles hängt von der Applikation ab."
Eine generelle Regel für die Beschleunigung gibt es nicht. Alle Varianten, von
n Rechenknoten liefern das Ergebnis schneller als in 1/n der Zeit
bis
n Rechenknoten sind langsamer als ein Einzelrechner
sind möglich. Die folgenden Abbildungen zeigen typisches Verhalten realer Anwendungen. Mit steigender Knotenzahl wird die Beschleunigung der Programmausführung immer geringer. Die Skalierbarkeit hängt nicht nur vom Programmcode selbst ab, sondern variert auch von Anwendungsfall zu Anwendungsfall stark. Das sollen ein paar praktische Beispiele, die auf einem Cluster von sieben P6/200 Doppelprozessormaschinen gerechnet wurden, zeigen:
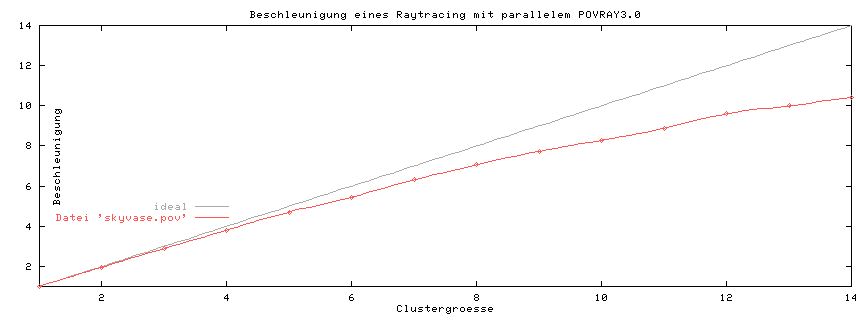
Raytracing gilt allgemein als sehr gut skalierbar. Aber auch hier gibt es Unterschiede. Eine einfache Szene, die ein Einzelrechner in z.B. fünf Sekunden rendert, lässt sich auf einem Cluster nicht beschleunigen. Sollen aber für eine Animation 500 solcher Szenen gerendert werden, lohnt sich der Einsatz eines Clusters. Als Faustregeln gelten:
Als Beispiel wurde der POVBENCH Standardbenchmark für POVRAY gerechnet. Es zeigt sich, dass eine Erhöhung der Rechenknotenzahl um den Faktor 14 zu einer Beschleunigung um den Faktor 10.4 führt.
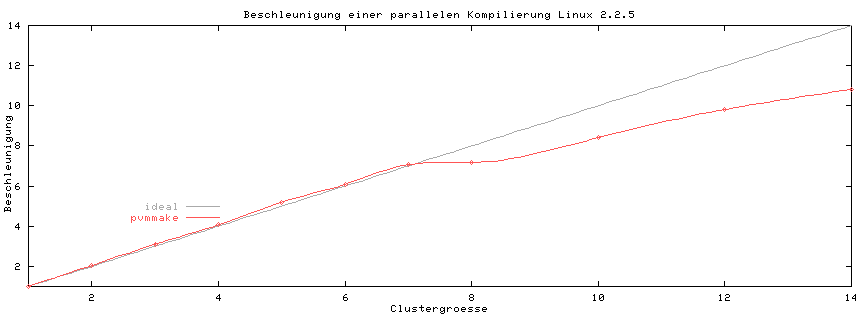
Das Programm PVMMAKE verteilt die Übersetzungsvorgänge auf die Rechenknoten und arbeitet deshalb vor allem bei der Übersetzung großer Programmpakete recht effizient. Als Beispiel wurde der Linux-Kernel in Version 2.2.5 parallel übersetzt. Die reine Übersetzungszeit eines Standardkernels (279 Dateien), die mit 14 Prozessoren erreicht wurde, lag bei 49s(!). Dies entspricht einer Beschleunigung um den Faktor 10.8 bei einer Erhöhung der Rechnerzahl um den Faktor 14. Der Leistungseinbruch beim Übergang der Clustergröße von sieben nach acht erklärt sich durch den Übergang von sieben Einzelprozessorsystemen zu vier Doppelprozessorsystemen. Das lässt vermuten, dass Einzelrechner in diesem Fall besser skalieren als Multiprozessorsysteme.
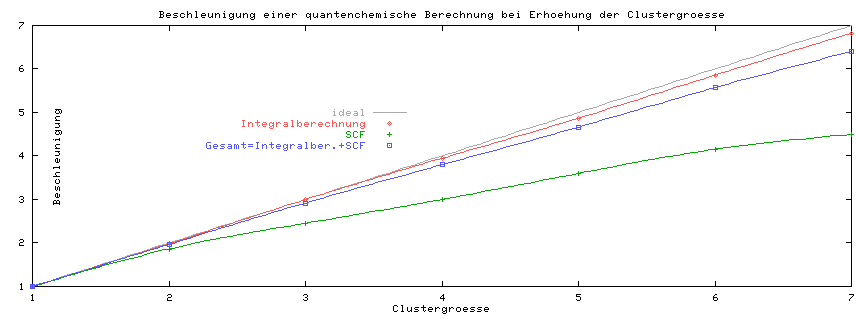
Das folgende Beispiel berechnet die Energie und Eigenschaften des Moleküls Methan. Es zeigt sich, dass die Integralberechnungen recht gut skalieren. Der parallele Festplatten-I/O skaliert eher schlecht. Da aber die Integralberechnung die meiste Zeit verbraucht, ist die Skalierung des Gesamtproblems noch gut. Diese Situation ändert sich, wenn größere Moleküle berechnet werden. Dann wird der Festplatten-I/O zum bestimmenden Faktor und die Skalierbarkeit des Gesamtproblems sinkt entsprechend.
Oft skaliert eine parallele Anwendung nur bis zu 4, 8, 16, ... Rechner zufriedenstellend und wird dann wieder langsamer. Wer also ein bestimmtes Problem mit einem Beowulf-Rechner lösen will, muss seinen Cluster auf das Problem anpassen und sein Optimum in Abhängigkeit der Variablen
finden. Das gelegentlich auftretende Phänomen, dass n Rechner eines Clusters parallele Programme schneller als in 1/n der Zeit der seriellen Variante durchführen, bezeichnet man als Superlinearität. Diese hat meist ihren Grund darin, dass bei der Parallelisierung die Problemgröße soweit sinkt, dass die Teilprobleme komplett in den Cachespeicher der einzelnen Rechenknoten passen. Dieser Effekt beschleunigt natürlich die Ausführung zusätzlich.
Da bei einem Cluster alle Rechenknoten relativ nahe beieinander stehen (SAN, System Area Network), entfallen bestimmte Beschränkungen, denen Standard-LAN-Technik unterliegt. Es haben sich deshalb in den letzten Jahren einige alternative Vernetzungsstrategien entwickelt, die vor allem Bandbreite und Latenz (minimaler Zeitbedarf für die Übertragung von Datenpaketen) verbessern sollen. Aufgrund des relativ hohen Preises kommen sie für Anfänger meist nicht in Frage. Sie können aber besonders bei Bandbreiten- bzw. latenzbeschränkten Problemen Vorteile bringen, die ihren Einsatz rechtfertigen. Die zwei kommerziell wichtigsten Varianten sind:
Auf der Softwareseite könnten folgende neueren Entwicklungen weite Verbreitung finden:
Neben der Tatsache, dass Beowulf-Cluster hauptsächlich als "Numbercruncher" entwickelt werden, gibt es noch ein Anwendungsgebiet, das sehr eng verwandt ist: Hochverfügbarkeitssysteme. Während die meisten Numbercrunching-Programme nach dem Master/Slave-Konzept arbeiten, geht es bei hochverfügbaren Systemen weniger um Lastverteilung als vielmehr darum, einen Dienst ausfallsicher zur Verfügung zu stellen. Dass Beowulf-Cluster auch dafür verwendet werden können, ist offensichtlich. Fällt ein Rechner eines Clusters aus, übernimmt ein anderer dessen Aufgaben. Ideal ist die Kombination von Leistungssteigerung durch Lastverteilung und Ausfallsicherheit durch Redundanz. Leistungsfähige und hochverfügbare Webserver auf einem Cluster lassen sich z.B. mit dem Programmpaket EDDIE realisieren.
Beowulf-Cluster finden schon mehr Verbreitung als vielfach angenommen. Hier eine kleine Liste berühmter Beowölfe:
Ganz besondere Beachtung verdient der Stone SouperComputer (kein Tippfehler). Es ist der ultimative Triumph des Beowulf-Konzeptes. Weit über hundert geschenkte(!) Rechner werden für die Bearbeitung großer nichttrivialer geographischer Probleme verwendet.
Die meisten Anwendungen für Beowulf-Cluster stammen aus dem technisch-wissenschaftlichen Bereich und haben somit meist nur für Spezialisten Bedeutung. Eine gewisse Ausnahme ist das populäre POVRAY und seine schon erwähnten parallelen Varianten PVMPOV und FLY. Ein neues Programm, das vielleicht noch populärer werden kann, ist mp3pvm. Es erlaubt die Nutzung von Beowulf-Clustern zur Erzeugung von MP3-Dateien.
Einen guten Einstieg in die Theorie der parallelen Programmierung unter Linux bietet die Parallelrechner-Seite der Uni Mannheim. Sehr nützlich und umfassend ist das Linux Parallel Processing HOWTO von Hank Dietz. Wer laufend auf dem neuesten Stand gehalten werden will, sollte die Mailinglisten Beowulf und Extreme Linux abonnieren. Newsgroups gibt es natürlich auch, nämlich: