von Michael Engel
Durch die Verfügbarkeit preiswerter, intel-basierter Mainboards ist ein Multiprozessor Linux-System auch für den Normalanwender kein unerreichbares Ziel mehr. SMP-Systeme werden in Zukunft weiter an Bedeutung gewinnen, da der Leistungszuwachs von Einzelprozessor-Systemen an physikalische Grenzen stößt. SMP unter Linux ist noch eine relativ neue Entwicklung, aber durchaus alltagstauglich - wenn auch noch viele Verbesserungen möglich sind.
- Ansätze zur Parallelisierung
Arten von Multiprozessorsystemen
Vor- und Nachteile von SMP
Das Cache-Konsistenzproblem
Verklemmungen...
SMP unter Linux
Glossar
Infos
Der Autor
Ansätze zur Parallelisierung [zurück]
Zur Einordnung des symmetrischen Multiprocessing innerhalb der Parallelverarbeitung sind zuerst einige Definitionen von verschiedenen Arten der Parallelverarbeitung angebracht:
SIMD (single instruction stream, multiple data stream) - alle Prozessoren führen den selben Code aus, jeder Prozessor hat dabei seine eingenen Daten.
MIMD (multiple instruction stream, multiple data stream) - jeder Prozessor führt eigenen Code auf eigenen Daten aus
SPMD (single program, multiple data) - eingeschränkte Version von MIMD, wobei jeder Prozessor das selbe Programm ausführt. Dabei kann aber jeder Prozessor einen differenten Kontrollfluß durch das Programm ablaufen.
Arten von Multiprozessorsystemen [zurück]
Zur Implementierung von Lösungen für parallelisierbare Probleme existieren verschiedene Systemmodelle. Einige der gebräuchlichsten sind:
SMP - Shared Memory
MP - symmetrische Multiprozessorkonfiguration, alle Prozessoren haben Zugriff auf den gesamten Speicher und alle Peripheriegeräte
Shared Disk MP - jeder Prozessor hat eigenen lokalen Speicher, nur Festplatten werden gemeinsam benutzt
Cluster - Shared Nothing MP - durch ein Kommunikationsmedium (z.B. Ethernet, ATM) verbundene, unabhängige Systeme. Kommunikation findet über spezielle Libraries wie PVM oder MPI statt (z.B. Beowulf Linux-Cluster der NASA [11])
Vor- und Nachteile von SMP [zurück]
Einer der wichtigsten Aspekte bei Multiprozessorsystemen ist die Skalierbarkeit. Diese ist abhängig von der Aufgabenstellung - einige Probleme sind besser skalierbar als andere. Generell darf man nicht davon ausgehen, daß eine n-fach höhere Anzahl an Prozessoren eine n-fache Leistungssteigerung ergibt. Im Durchschnitt ist eine Steigerung um einen Faktor von 1.5-1.8 bei Verdoppelung der Prozessorzahl zu erwarten. Je nach Problemstellung und Implementierung sind aber auch Effekte von Leistungsreduzierung (bei zu hohem Verwaltungsaufwand) bis mehr als n-fache Steigerung (durch Caching-Effekte) möglich.
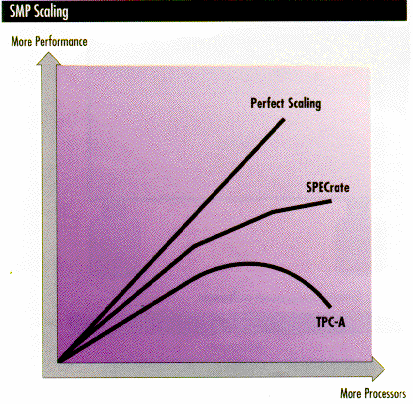
Vorteile von SMP:
- Gesamtsystem erscheint für jeden Prozeß wie ein Einprozessorsystem
- keine Programmanpassungen vorhandener Software notwendig. die Vorteile von SMP können durch Anpassung der Software bei Bedarf dennoch genutzt werden
- durch die gemeinsame Verwendung von Hauptspeicher und Peripheriegeräten sind SMP-Systeme recht preiswert realisierbar
- Relativ großer Overhead bei Betriebssystem und Hardware notwendig, um Einprozessor-Illusion für Applikationen zu erzeugen
- Hohe Auslastung des Busses oder Switches, der die Prozessoren mit gemeinsam benutztem Speicher und Peripheriegeräten verbindet
- Der Zugriff auf von mehreren Prozessoren gemeinsam genutzte Speicherbereiche muß durch sog. Locks geregelt werden -> erhöhter Verwaltungsaufwand für das Betriebssystem.
Das Cache-Konsistenzproblem [zurück]
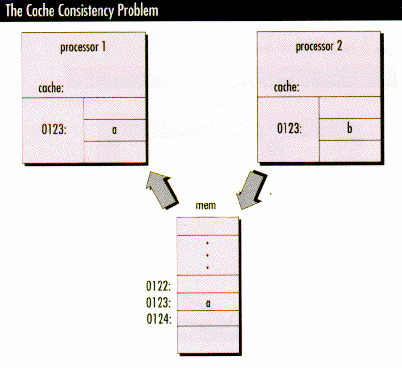
Eines der grundlegenden Probleme aller SMP-Systeme ist die Cache-Konsistenz.
Das Bild zeigt ein Beispiel. Es laufe ein Prozeß P1 auf Prozessor
1 und ein Prozeß P2 auf Prozessor 2. Die Prozesse P1 und P2 arbeiten
zusammen an einem Problem und teilen sich einen Speicherbereich. Nun trete
die folgende Abfolge von Ereignissen ein:
- Prozeß P1 lädt Adresse 123, die das Zeichen "a" beinhaltet
- Prozeß P2 speichert das Zeichen "b" in Adresse 123
- Prozeß P1 lädt Adresse 123 nochmals
Wie folgenden im Bild gezeigt, muß eine Logik an jedem Prozessor-Bus Interface existieren, die jedesmal eine Meldung über den Bus verbreitet, wenn sich ein Wert in seinem Cache geändert hat. Diese Logik reagiert auch auf solche Meldungen der anderen Prozessoren. Jedesmal, wenn erkannt wird, daß ein anderer Prozessor den Wert einer Speicherzelle geändert hat, die im eigenen Cache vorhanden ist, wird dieser Cache-Eintrag invalidiert. Dadurch weiß der Prozessor, daß er den Wert an einer anderen Stelle suchen muß.
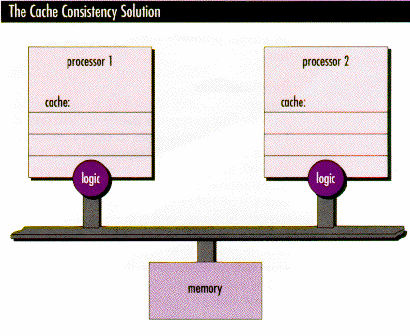
In unserem Beispiel erhält P1 beim Versuch, Adresse 123 zum zweiten Mal zu lesen, einen cache miss und muß anderweitig nach dem Wert suchen. Die zusätzliche Überwachungslogik legt fest, wo Prozeß P1 suchen muß, um den korrekten Wert für Adresse 123 zu finden. Wenn der neue Wert in den Speicher geschrieben wurde, wird Prozeß P1 den Wert aus dem Speicher holen. Falls der neue Wert noch nicht in den Speicher geschrieben worden ist, wird Prozeß P1 ihn aus dem Cache von Prozessor 2 holen.
Da die gegenseitige Invalidierung die Anzahl der cache misses erhöht und das Überwachungsprotokoll zur Erhöhung des Verkehrs auf dem Bus beiträgt, reduziert die Lösung des Cache-Konsistzenz-Problems die Leistung und Skalierbarkeit aller Prozessoren.
Verklemmungen... [zurück]
Eines der weithin bekannten Probleme von SMP ist die Aufrechterhaltung der Datenkonsistenz. Betrachten wir das klassische Beispiel einer doppelt verketteten Liste. Entfernen eines Elementes aus der Liste erfordert, daß zwei Zeiger aktualisiert werden:
- Der Vorwärtszeiger des dem zu löschenden Element vorgehenden Elementes
- Der Rückwärtszeiger des Elementes, das auf das zu löschende Element folgt
Das Problem: Integrität der Daten
Ein kritischer Abschnitt ist ein Abschnitt von Code, der gemeinsam genutzte Daten modifiziert und deshalb nicht von mehr als einem Prozeß gleichzeitig ausgeführt werden darf. Ein Prozeß muß also warten bis der andere Prozeß seinen kritischen Abschnitt beendet hat. Die beiden kritischen Abschnitte müssen also serialisiert werden.
Die Lösung: Locks
Prinzipiell ist ein Lock einfach ein Bit im Speicher, das von Prozessen genutzt wird, um Zugang zu kritischen Abschnitten zu regeln. Wenn ein Prozeß einen kritischen Abschnitt betreten will, prüft er den entsprechenden Lock. Wenn das Bit aus ist, schaltet der Prozeß es an und betritt dann den kritischen Abschnitt. Wenn das Bit an ist, wartet der Prozeß bis das Bit aus ist. Jeder Prozeß muß das Bit beim Verlassen des kritischen Abschnittes zurücksetzen.
Spinlocks vs. Blockierende Locks
Wenn ein Prozeß einen Lock haben möchte, der bereits von einem anderen Prozeß gehalten wird, muß er warten. Ein spin lock erlaubt es dem wartenden Prozeß den Prozessor zu behalten, wobei wiederholt die Prüfung des Bits in einer kleinen Schleife (spin) solange, bis der Lock verfügbar wird. Spin locks sind nützlich für Locks, die nur für sehr kurze Zeit gehalten werden. Ein blockierender Lock hält den Prozeß so lange an, bis der Lock frei ist und stellt in dann in die run queue zurück. Dies ist sinnvoll bei Locks, die für längere Zeit gehalten werden sollen.
Warten auf Locks Warten vermindert immer die Systemleistung, egal wie es implementiert ist. Wenn ein spin lock benutzt wird, ist der Prozessor beschäftigt, tut aber keine "sinnvolle" Arbeit (kein Beitrag zum Systemdurchsatz). Wenn ein blockierender Lock benutzt wird, kommt der Overhead für Kontext-Switching und Dispatching und der damit verbundene Anstieg von cache misses zum Tragen.
Granularität von Locks
Die Länge der Zeit, die ein Lock besetzt ist, ist eine Funktion der Anforderungshäufigkeit und der Zeit, die der Lock gehalten wird, wenn er einmal angefordert wurde. Einer der effizientesten Wege um Wartezeit auf Locks zu reduzieren ist es, die Größe dessen zu beschränken, worauf gewartet wird: seine Granularität. Reduzierung der Granularität ist einer der wichtigsten Punkte der SMP-Entwicklung in den aktuellen Entwickler-Kernels.
SMP unter Linux [zurück]
Nach der doch etwas theoretischen Einführung in die Problematik wenden wir uns nun SMP unter Linux zu. Erste Unterstützung für SMP wurde in späten 1.3.x-Kernelversionen durch Alan Cox implementiert. Erstes Portierungsziel war ein Dual-Prozessor Pentium-System, kurze Zeit später kam Unterstützung für Mehrprozessor SPARCstations mit sun4m-Architektur hinzu. Erste mit SMP benutzbare Kernel-Versionen waren z.B. 2.0.9 und 2.0.14, der 2.0.33er-Kernel hat stabilen SMP- Support, aktuelle 2.1.x-Kernel haben zudem wesentliche Verbesserungen in Hinblick auf SMP-Performance erfahren.
Momentan werden MPS 1.1 und 1.4-konforme [7] 486DX,Pentium/Pro/II-basierte SMP-Systeme sowie HyperSPARC-basierte Multiprozessor-Systeme von Sun (SPARCstation 10, 20) unterstützt, DEC Alpha, Motorola/IBM Power-PC und UltraSPARC MP-Systeme sind bei den entsprechenden Gruppen in Arbeit. Erster Support für einige Alpha SMP-Systeme ist z.B. ab Kernel 2.1.92 vorhanden.
SMP auf intel-basierten Systemen
Erste auf intels 80386 basierte Multiprozessor-Systeme kamen ca. 1987 auf den Markt, die Firma Sequent war einer der Vorreiter auf diesem Gebiet mit den (sic!) Symmetry-Systemen. Verschiedene Hersteller haben seitdem SMP-Systeme auf intel-Basis gebaut, die jeweils zueinander inkompatible Implementierungen waren. Diese Situation hat sich mit der Einführung der MPS 1.1-Spezifikation durch intel grundlegend geändert, seitdem sind fast ausschließlich MPS-kompatible Systeme erhältlich. Diese Spezifikation wurde 1994 überarbeitet und als MPS 1.4 bezeichnet.
Dies erleichterte die Implementierung für die Linux-Entwickler sehr. Aktuelle Kernel laufen auf jedem MPS 1.1 und 1.4-kompatiblen SMP-System, dessen Prozessoren on-chip FPUs besitzen. Dabei werden theoretisch bis zu 16 CPUs unterstützt, getestet wurde Linux bisher meines Wissens auf Systemen mit bis zu 6 Prozessoren (z.B. von ALR).
Leider sind Prozessoren der Mitbewerber von intel (AMD K5,K6, Cyrix 6x86 etc.) mit aktuellen Boards nicht im Multiprozessor-Betrieb einsetzbar, da APIC (die verbesserte Interrupt-Controller Spezifikation) von intel patentiert ist. Non-intel Prozessoren verwenden daher ein differentes Protokoll namens OpenPIC - leider existiert bisher noch kein Chipsatz, der dies unterstützt.
Folgende Einschränkungen gilt es bei intel-basierten SMP-Systemen zu beachten:
- Bei den meisten Pentium MP-Boards teilen sich beide CPUs einen second- level-Cache, was zu größeren Performanceeinbußen führen kann
- Pentium II-Prozessoren sind designbedingt auf Konfigurationen mit maximal zwei CPUs pro System eingeschränkt, zudem beträgt die maximale cacheable Area 512 MB.
cat /proc/cpuinfo
unter Linux oder das Tool ctcm [8] des Computermagazins c't.
Der für MP-Systeme am besten geeignete intel-Prozessor ist momentan der Pentium Pro, da er einerseits keine künstliche Beschränkung der Prozessoranzahl hat und andererseits bis zu 4 GB Hauptspeicher verwalten kann.
SMP auf SPARCs
Sun vertreibt seit einigen Jahren SPARC-basierte Multiprozessorsysteme. Die erste verfügbare Workstation mit mehreren CPUs war die SPARCstation 10, Nachfolgemodelle sind z.B. SPARCstation 20 und UltraSPARC 2. Zudem bietet Sun im Server-Bereich SMP in fast allen Systemen zumindest optional an.
Linux unterstützt auf SPARC momentan alle multiprozessor-fähigen Konfigurationen der Sparc 10 und 20 (einige ältere Prozessormodule von Sun, z.B. SM30 und SM40, sind aufgrund von Designfehlern nicht SMP-fähig). An der Unterstützung für UltraSPARC-basierte Systeme wird mit Hochdruck gearbeitet, Details sind unter [9] nachzulesen.
Compilieren eines SMP-Kernels
Die einzigen notwendigen Änderungen sind im Makefile des Kernels vorzunehmen, hier sind die Kommentare vor der Definition der Variablen SMP und SMP_PROF zu entfernen:
# SMP = 1
#
# SMP profiling options
SMP_PROF = 1
Der Kernel wird dann z.B. mit
% make dep clean
% make -j4 zImage modules modules_install
compiliert. Der Parameter nach -j legt fest, wieviele Prozesse von make gleichzeitig gestartet werden. Wenn -j ohne Parameter aufgerufen wird, startet make so viele Prozesse wie möglich - dabei kann es vorkommen, daß der Übersetzungsvorgang mangels Speicher abbricht. Der dependency-Schritt (make dep) ist dabei nicht parallelisierbar!
Danach ist der Kernel wie gehabt mit LILO oder loadlin zu installieren. Für alle Fälle sollte man noch eine Kernelversion ohne SMP-Unterstützung zur Hand haben.
Ein Problem, das vor allem in 2.0.x-Kernelversionen auftritt, ist eine zu schnell laufende Systemuhr. Diesem Problem wird in 2.1.x-Kerneln Rechnung getragen. Es empfiehlt sich auf jeden Fall, beim Konfigurieren des Kernels "enhanced realtime clock support" anzuwählen, zudem ist die Synchronisierung der Systemuhr an einem Time-Server oder einem DCF77- Empfänger (z.B. mit xntpd) zu empfehlen.
Und jetzt ???
Woran kann man nun erkennen, daß Linux den zweiten Prozessor auch erkannt hat ? Einige Dateien im /proc-Dateisystem geben Auskunft über die Konfiguration des Systems:
/proc/cpuinfo zeigt einen Eintrag für jeden Prozessor an, dies ist die Ausgabe auf meinem Dual-Pentium 133:
processor :
0
cpu family : 5
model
: Pentium 75+
vendor_id
: GenuineIntel
stepping
: 12
[...]
flags
: fpu vme de pse tsc msr mce cx8 apic
bogomips
: 53.04
processor :
1
cpu family : 5
model
: Pentium 75+
vendor_id
: GenuineIntel
stepping
: 12
[...]
flags
: fpu vme de pse tsc msr mce cx8 apic
bogomips
: 53.04
Linux verteilt auch die Interrupts auf die einzelnen Prozessoren. Dies ist gut in /proc/interrupts zu erkennen:
CPU0 CPU1
0: 1193305
395 XT-PIC
timer
1:
1 1 IO-APIC-edge
keyboard
2:
0 0 XT-PIC
cascade
4:
6 18 IO-APIC-edge
serial
5:
1524 1196 IO-APIC-edge
soundblaster
7:
908092 908114 IO-APIC-edge
3c509
13:
4 0 XT-PIC
fpu
17:
19391 19353 IO-APIC-level
ncr53c8xx
NMI:
0
IPI:
0
Ein schönes Tool, um die Systemauslastung anzuzeigen, ist xosview [5]. Auf einem 4-Prozessor PentiumPro-System sieht die Ausgabe z.B. wie folgt aus:
Ausnutzung von SMP Das schönste SMP-System nützt nichts, wenn man nur eine einzige, nicht SMP-angepaßte Applikation als einziger User auf dem System benutzt. SMP kann in folgenden Fällen Vorteile bringen:
- Viele Benutzer arbeiten gleichzeitig auf dem System
- Aufgabenstellungen bestehen aus vielen separaten Prozessen (z.B. Compilieren eines großen Projektes)
- Applikationen können durch Nutzung mehrerer Prozessoren (z.B. durch Multithreading) Geschwindigkeitsvorteile erzielen
Zur Ermittlung der erreichbaren Beschleunigung wurde der GNU-C Compiler gcc 2.7.2.2 auf einem PentiumPro 200-System mit einem, zwei bzw. vier Prozessoren und 512 MB RAM mit
% make -j<n> bootstrap LANGUAGES="c c++ objc"
compiliert. Dabei ergaben sich folgende Zeiten:
1 CPU 2 CPUs 4 CPUs gcc 2.7.2.3 11:53 6:07 3:13 Linux 2.1.102
Multithreading
Mittlerweile existieren mehrere Libraries, die SMP-unterstütztes Threading anbieten. Die LinuxThreads Library von Xavier Leroy [3], die mittlerweile in glibc2 (aka libc6) integriert ist, ist dafür gut zu verwenden. LinuxThreads ist eine recht komplette und solide Implementation des POSIX 1003.1c Threading-Standards. Dabei wird - im Gegensatz zu den meisten POSIX-Thread Portierungen - der clone()-Systemaufruf des Linux-Kernels verwendet. POSIX-Kompatibilität bedeutet, daß viele Applikationen von anderen Systemen mit relativ geringem Aufwand portiert werden können und zudem verschiedene Tutorien zur Programmierung verfügbar sind. Kurzum, LinuxThreads ist definitiv das Paket, das zur Entwicklung großer Programmpakete eingesetzt werden sollte.
Die grundlegende Programmstruktur bei Verwendung der LinuxThreads Library ist:
- Programm als einzelnen laufenden Prozeß starten
- Initialisieren aller benötigten Locks. POSIX Locks werden als Variable des Typs pthread_mutex_t deklariert. Jeder Lock muß mit pthread_mutex_init(&lock,val) initialisiert werden.
- Ein neuer Thread wird durch Aufruf einer Library-Routine initiiert. Dabei werden als Argumente die auszuführende Funktion und die zu übergebenden Argumente angegeben. Jeder Thread wird durch eine Variable des Typs pthread_t identifiziert. Um einen Thread zu erzeugen, der die Funktion f() aufruft, benutzt man pthread_create(&thread,NULL,f,&arg).
- parallelen Code laufen lassen. Dabei muß darauf geachtet werden, daß kritische Abschnitte mit pthread_mutex_lock(&lock) und pthread_mutex_unlock(&lock) umgeben werden.
- Zum Aufräumen nach der Beendigung eines Threads die Funktion pthread_join(thread,&retval) verwenden.
- Beim Compilieren des Codes -D_REENTRANT verwenden.
SMP Symmetrischer MultiProzessor. Ein System aus mehreren identischen Prozessoren, die sich Hauptspeicher und Peripheriegeräte teilen. Advanced Programmable Interrupt Controller. Im Gegensatz zum vom PC APIC bekannten 8259 Interrupt Controller ist der APIC multiprozessor-fähig. Von intel patentiert.
OpenPIC Alternative Implementierung eines SMP-fähigen Interrupt- Controllers in x86-kompatiblen Prozessoren von AMD, Cyrix etc. Scalable Processor ARChitecture. Von Sun 1988 eingeführte
SPARC RISC-Prozessor-Familie, die Basis für alle aktuellen Workstations von Sun ist. Asynchronous Transfer Mode.
ATM Hochgeschwindigkeits-Netzwerktechnologie, die für die Übertragung von zeitsynchronen Audio- und Videodaten optimiert ist.
Infos [zurück]
[1] http://www.irisa.fr/prive/mentre/smp-faq/
Linux-SMP FAQ
[2] http://yara.ecn.purdue.edu/~pplinux/PPHOWTO/pphowto.html
Linux Parallel Processing HOWTO
[3] http://pauillac.inria.fr/~xleroy/linuxthreads/
Xavier Leroy's pthreads Library
[4] http://www.cs.inf.ethz.ch/~rauch/procps.html
procps
[5] http://lore.ece.utexas.edu/~bgrayson/xosview.html
xosview
[6] http://www.interlog.com/~mackin/linux-smp.html
Linux-SMP performance
[7] http://www.intel.com/design/pro/datashts/242016.htm
MPS 1.4-Spezifikation von intel
[8] ftp://ftp.heise.de/pub/ct/pcconfig/ctcm16l.zip
Pentium-Testprogramm der c't
[9] http://www.geog.ubc.ca/s_linux.html
Linux auf SPARCs
[10] http://www.eecis.udel.edu/~ntp/
xntpd
[11] http://cesdis.gsfc.nasa.gov/beowulf/
BeoWulf Cluster von Donald Becker bei der NASA
Der Autor [zurück]
Michael Engel studiert Technische Informatik an der Uni-GH Siegen und ist Sysadmin für mehrere Sparcs. Wenn er nicht gerade News liest, ist er bei der Unix-AG oder seiner Rechnersammlung tätig und schraubt dort mit Vorliebe an alten PDP11en, VAXen oder Unix-Kisten. Zudem arbeitet er an der Linux-Portierung auf DECstations mit (http://decstation.unix-ag.org) und implementiert mit Kommilitonen einen ATM-basierten Video-Server unter Linux. Zu erreichen ist er unter engel@unix-ag.org.
Copyright © 1998 Linux-Magazin Verlag