von Roger Butenuth
Linux Rechner erlauben es, preisgünstig Rechenleistung zur Verfügung zu stellen. Verschiedene Universitäten haben mit schnellen Netzen auch schon aus PCs bestehende Parallelrechner aufgebaut, am bekanntesten ist vermutlich das Beowulf-Projekt, in dem die Knoten per Fast Ethernet (100 Mbit/s) vernetzt sind. An der Universität Paderborn steht momentan ein Linux Cluster aus acht Doppelprozessor PentiumPro PCs, die mit SCI (Scalable Coherent Interface) vernetzt, einen Hochgeschwindigkeitsnetz mit 4 Gbit/s Übertragunsrate. Der Vortrag wird sich auf die unter Linux zur Verfügung stehende Software konzentrieren, die es ermöglicht, rechenzeitintensive Anwendungen effizient auszuführen.
Bei dem Begriff "High Performance Computing" oder auch Hochleistungsrechnen denken die meisten sicher an große Vektor- oder Parallelrechner von Cray und anderen Firmen, die in riesigen, abgeschotteten und klimatisierten Räumen stehen, weniger an Linux und "kleine" Rechner" unter dem Schreibtisch". Vergleicht man die einzelnen Knoten von Parallelrechnern mit aktuellen Intel, Sparc oder Alpha basierten Systemen, so sieht man schnell, daß sie ähnliche Leistungsdaten haben, aber preislich weit auseinanderliegen.
Extrem hohe Stückzahlen in der PC-Branche ermöglichten in den letzten Jahren konkurrenzlos günstige Preise (oft leider auch mit mieser Qualität verbunden). Es liegt daher nahe, aus Standardkomponenten preiswerte "Parallelrechner" zusammenzubauen. Man muß dabei jedoch im Auge behalten, daß man die Gesamtleistung eines Rechners nicht nur nach der Prozessorleistung beurteilen darf. Viele Algorithmen arbeiten mit großen Datensätzen, viel größer als der Prozessorcache, so daß die Bandbreite des Hauptspeichers eine wichtige Rolle spielt. Erst kürzlich konnte hier in PCs mit der Einführung des 100 MHz Speicherbusses eine Verbesserung geschaffen werden. Leider ist dessen Leistungsfähigkeit immer noch deutlich geringer als die von UltraSparc basierten SUN-Workstations.
Schnelle Prozessoren benötigen schnelle Netze
Je mehr Knoten man koppelt, desto wichtiger wird auch das Verbindungsnetzwerk. Oft steckt in diesem die Hälfte der Gesamtkosten eines Systems, aber was helfen ansonsten schnelle Prozessoren, wenn sie die meiste Zeit doch nur auf Daten von ihren Nachbarprozessoren warten? Bei den Netzen sind zwei Größen ausschlaggebend: Der Durchsatz, meist in Bit pro Sekunde gemessen, sowie die Latenzzeit, in Mikrosekunden gemessen. Der Begriff Durchsatz - oft auch Bandbreite genannt - dürfte bekannt sein, die Latenzzeit wird dagegen oft nicht beachtet. Sie gibt die Zeit an, die vom Aufruf der Sendefunktion bis zur Rückkehr der Empfangsoperation für eine kurze Nachricht vergeht. Während "gewöhnliche" Netze wie Ethernet oder Fast-Ethernet mit einen Durchsatz von 10 bzw. 100 Mbit/s und einer Latenzzeit von 250 Mikrosekunden aufwarten, glänzen speziell für Parallelverarbeitung gedachte Netze wie SCI mit einem Durchsatz von bis zu 4 Gigabit/s und einer Latenzzeit von weniger als 10 Mikrosekunden.
Woher kommen diese gewaltigen Unterschiede? Bei der Bandbreite sind sie in der Hardware zu suchen: Da für paralleles Rechnen nur geringe Distanzen überbrückt werden müssen (alle Rechner stehen gewöhnlich in einem Raum), läßt sich die Hardware zu diesem Zweck optimieren, zum Beispiel durch bitparallele statt serieller Übertragung. Bei größeren Distanzen wäre dies durch hohe Kabelpreise nicht mehr wirtschaftlich. Die Unterschiede in der Latenzzeit dagegen sind in der Software zu suchen: Auf Ethernet, FDDI oder ATM setzt praktisch immer TCP/IP als Protokollstack auf. Die Abarbeitung des gesamten Stacks - verbunden mit Kernaufrufen und Interruptbehandlung - kostet dabei sehr viel CPU-Zeit. Der "Trick" zur Reduktion der Latenzzeit besteht darin, TCP/IP und das Betriebssystem zu "umgehen". Es ist dazu notwendig, Teile der Hardware für Anwendungen (beziehungsweise Bibliotheken) direkt in den Benutzeradreßraum einzublenden. Die Hardware muß natürlich so entworfen sein, daß man mit dem Zugriff auf sichere Teile auskommt und nicht den Zugriff auf sämtliche Teile freigibt, da ansonsten von einer Anwendung aus der gesamte Rechner lahmgelegt werden könnte. Netze, die diese Technik anwenden, sind unter anderem SCI (Scalable Coherent Interface) und Myrinet. SCI ist durch IEEE standardisiert, während Myrinet ein proprietäres Produkt der Firma Myricom ist. Für SCI gibt es momentan auch nur einen Anbieter (Dolphin), mit zumindest einem weiteren (ISS) ist jedoch zu rechnen. Die fehlende Konkurrenz und die geringen Stückzahlen haben (leider) relativ hohe Preise zur Folge.
Parallele Software
Schnelle Prozessoren und Netze sind nur die halbe Miete: Für schnelle Problemlösungen benötigt man auch die entsprechende Software. Wie sollte man daher vorgehen, wenn man ein rechenzeitaufwendiges Problem zu lösen hat? Aus langer (leidvoller?) Erfahrung kann man einen wichtigen Tip geben: Nicht blindlings einen Parallelrechner kaufen und mutig parallelisieren! Folgendes Szenario ist dann nämlich vorprogrammiert: Wenn das Programm für den gekauften Parallelrechner (endlich) fertig ist, kann man bereits einen sequentiellen Rechner kaufen, der für den halben Preis des Parallelrechners die gleiche Leistung liefert. Nicht zu vernachlässigen sind auch die Verluste, die beim Einsatz vieler Prozessoren entstehen: Genausowenig wie 1000 Maurer ein Haus an einem Tag fertigstellen können, ist auch ein Rechner mit 1000 Prozessoren nicht notwendigerweise in der Lage, ein Problem um den Faktor 1000 schneller zu lösen.
Nach all diesen pessimistischen Warnungen sollen nun einige positive Ideen und Ansätze folgen. Wenn man festgestellt hat, daß auch der schnellste Einprozessorrechner die eigene Anwendung nicht in angemessener Zeit abarbeitet, kann man sich zuerst auf begrenzte Parallelität mit Mehrprozessormaschinen beschränken: Doppelprozessorboards für PentiumII CPUs sind für moderate Preise erhältlich, erst für Vierprozessormaschinen - die meistens als Server ausgelegt sind - zahlt man im PC-Bereich eher ungewohnte Preise. Der aktuelle stabile Linux-Kernel (2.0.33) unterstützt noch nicht automatisch mehrere Prozessoren, dazu muß im zentralen Makefile das Kommentarzeichen vor der Zeile SMP=1 entfernt werden. Hat man daraufhin den Kernel neu übersetzt und installiert, sollte der Befehl cat /proc/cpu Auskunft über alle Prozessoren geben.
Threads
Nun können zwar mehrere Programme gleichzeitig ausgeführt werden, ein gewöhnliches Programm, das aus nur einem Prozeß besteht, wird dadurch jedoch nicht schneller. Der einfachste Ansatz zur Nutzung mehrerer Prozessoren besteht im Einsatz von Threads . Ein Thread ist ein weiterer Aktivitätsfaden im Adreßraum des erzeugenden Prozesses, bis auf den Stack und einige Verwaltungsdaten teilt er sich alle Betriebsmittel (offene Dateien, Speicher, Netzverbindungen, etc.) mit allen anderen zum selben Prozeß gehörenden Threads. Der geringe Aufwand pro Thread hat auch zu dem alternativen Namen Leichtgewichtsprozeß geführt, im Gegensatz zu den in Unix üblichen "schweren" Prozessen mit all ihren angehängten Attributen und Betriebsmitteln. Threads müssen nicht durch ein ganzes Programm hindurch genutzt werden: Es bietet sich an, zuerst mit Hilfe eines Profilers die rechenzeitintensiven Teile zu suchen und nur dort mit Hilfe paralleler Threads zu parallelisieren. Die notwendigen Threads lassen sich mit pthread_create erzeugen. Nach Abschluß des parallelen Teils können mit der Funktion pthread_join alle Aktivitätsfäden wieder zu einem einzigen "zusammengeflochten" werden.
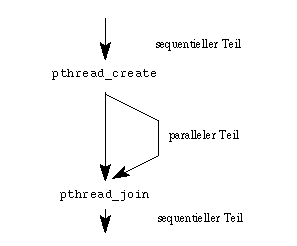
Mit Threads ist es leicht möglich, nur kleine Programmteile zu parallesieren. Der Rest des Programmes - im Idealfall der größte Teil - kann unverändert bleiben.
Message Passing
Reicht einem die Kapazität einer Mehrprozessormaschine nicht aus oder möchte man existierende koppeln - eventuell um nachts nicht benutzte Computer auszulasten - kommt man um aufwendigere Programmiermodelle nicht herum. Der Hardwareaufwand ist gleich Null, falls man ein bereits vorhandenes Ethernet oder Fast-Ethernet nutzen kann. Welche Programmiermodelle kann man nun nutzen? Da auf Hardwareebene kein gemeinsamer Speicher mehr vorhanden ist, bietet es sich an, mit Nachrichtenaustausch ( message passing) zu arbeiten. Im Laufe der Jahre haben sich dafür zwei Standards herausgebildet: PVM (parallel virtual machine) und MPI ( message passing interface). Sie unterscheiden sich zwar in vielen Details, basieren aber auf dem gleichen Konzept: Man erstellt - wie im sequentiellen Fall - ein Programm, das dann allerdings später auf mehreren Computern ausgeführt wird. Die einzelnen Kopien des Programmes unterscheiden sich nach dem Start nur durch eine Zahl, den sogenannten Rang, der von 0 bis zur Anzahl der Kopien minus 1 läuft. Aufgrund des Rangs können die Programmkopien dann unterschiedliche Teile des Problems lösen. Durch Sende- und Empfangsaufrufe lassen sich Daten zwischen den einzelnen Prozessen austauschen, so daß auch gemeinsame Arbeit an einem Problem möglich ist.
Der Nachrichtenaustausch wird bei PVM (meistens) über UDP/IP abgewickelt, bei MPI über TCP/IP. Die Werte, die sich für Latenz und Durchsatz ergeben, können daher nicht besser als die von UDP/IP beziehungsweise TCP/IP sein. Für viele Anwendungen mit wenig Kommunikation ist dies tragbar, andere lassen sich damit nicht sinnvoll parallelisieren. Ein positives Beispiel ist der Raytracer Povray, von dem eine mit PVM parallelisierte Variante existiert. Die Parallelisierungsstrategie ist recht simpel: Das zu berechnende Bild wird in Kacheln zerlegt, wobei die Anzahl der Kacheln deutlich größer als die Anzahl der Prozessoren sein sollte. Der erste Prozeß fungiert nun als Master, er verteilt die Arbeit an die restlichen Prozesse (Worker) in Paketen der Größe einer Kachel. Wenn einer der Worker eine Kachel fertig gerechnet hat, schickt er das Ergebnis an den Master zurück, der ihm daraufhin ein neues Arbeitspaket schickt. Es gibt viele andere Probleme, die sich ähnlich bearbeiten lassen. Wann dies auch effizient ist, kann man sich leicht überlegen: Wenn die Zeit zur Bearbeitung eines Paketes in der Größenordnung der Latenzzeit liegt, warten die Prozessoren einen erheblichen Teil der Zeit auf neue Arbeit, so daß mit keiner guten Effizienz zu rechnen ist. Sind die Zeiten zur Bearbeitung eines Paketes dagegen groß gegenüber der Latenz und die zu übertragenden Daten auch nicht so umfangreich, daß durch die begrenzte Bandbreite Engpässe auftreten, dann kann man eine Zeitersparnis durch die Parallelisierung erwarten.
Cluster Lösungen
Statt existierende Computer zu benutzen, kann man natürlich auch einen dedizierten Cluster nur für rechenintensive Programme aufstellen. Die einzelnen Computer lassen sich dann speziell auf die zu bearbeitenden Problem optimieren, so sind eventuell nur sehr kleine Festplatten notwendig. Wenn sie nur als "Rechenknechte" eingesetzt werden, muß auch nicht jeder mit einer eigenen Tastatur, Grafikkarte und Monitor ausgestattet werden. Solche Cluster werden an verschiedenen Forschungseinrichtungen eingesetzt: Das Max-Planck-Institut in Saarbrücken besitzt einen Cluster aus 16 PentiumPro PCs, bei denen jeder zur Kommunikation mit vier Fast-Ethernet und einer Ethernet-Karte ausgestattet ist. Die Ethernet-Karte dient zur Kommunikation mit der Außenwelt, während mit den Fast-Ethernet-Karten ein Torus der Größe vier mal vier aufgebaut ist. Die direkten Punkt-zu-Punkt-Verbindungen machen den Betrieb ohne Fast-Ethernet Hub oder Switch möglich. Ein Hub wäre in dieser Konfiguration ein Engpaß (alle Knoten teilen sich 100 MBit/s Bandbreite), ein Switch wurde (damals) als zu teuer angesehen. Sehr bekannt geworden ist auch das Cluster-Projekt Beowulf der NASA. Dort wurden von Donald Becker - quasi nebenbei - auch Treiber für verschiedene Fast-Ethernet-Karten entwickelt, die inzwischen den Weg in den offiziellen Linux Kern gefunden haben. Beowulf Cluster sind in der Netzwerkhardware nicht festgelegt, es finden sich aber oft Ethernet und Fast-Ethernet, schnellere Hardware, wie zum Beispiel Myrinet, wird allerdings auch eingesetzt.
High Speed Netze: Myrinet und SCI
Mit Myrinet wären wir dann schon beim nächsten Thema, nämlich einer der Netzwerktechnologien, die deutlich leistungsfähiger als lokale Netze ist, dafür aber nur über geringere Distanzen arbeitet und in anderen Preisregionen liegt. Myrinet verwendet Punkt-zu-Punkt Verbindungen mit einer Bandbreite von 1,28 Gigabit/s. Es wird also ein Switch benötigt, der Daten zwischen den Verbindungen weiterleitet. Software existiert für verschiedene Betriebssysteme, natürlich auch für Linux. Dies sind zum einen Pakettreiber für TCP/IP, die zwar einen sehr guten Durchsatz bieten, aber leider eine relativ hohe Latenz haben. Wenn man einen Myrinet Cluster zum parallelen Rechnen einsetzen will, sollte man auf eine der verfügbaren Message-Passing-Bibliotheken zurückgreifen, zum Beispiel PVM. Dies ermöglicht auch ein schrittweises vorgehen: Man kann seine Software zuerst mit PVM auf gewöhnlichem Ethernet laufen lassen und später, falls sich Ethernet als zu langsam erweist, auf Myrinet wechseln. Die Universität Karlsruhe hat mit ParaStation einen ähnlichen Ansatz wie Myrinet verfolgt, allerdings hat dort jede PCI-Karte gleich zwei Ein- und Ausgänge, so daß keine separaten Switches mehr notwendig sind. Die Latenz liegt in ähnlichen Regionen wie bei Myrinet, der Durchsatz ist geringer, was darauf zurückführen sein dürfte, daß an dem Projekt ParaStation schon länger gearbeitet wird und damals die schnellere Technologie noch nicht verfügbar war.
Einen vollständig anderen Ansatz verfolgt SCI (Scalable Coherent Interface), eine per IEEE-Standard definierte Schnittstelle. SCI ist als Nachfolger von Bussystemen entworfen worden, da Busse immer mehr an ihre physikalischen Grenzen stoßen: Je höher die Taktfrequenzen werden, desto weniger Geräte kann man anschließen, was man schon an der begrenzten Anzahl von PCI-Slots in PCs sieht. Das von SCI verwendete Protokoll, ein sogenanntes Split Transaction Protokoll, ist dem moderner Busse (z.B. PentiumPro Bus, GTL+ Protokoll) sehr ähnlich: Beispielsweise wird ein Speicherzugriff in einen Request und einen Reply unterteilt. Diese Unterteilung ermöglicht es, während eines (relativ langsamen) Speicherzugriffes das Übertragungsmedium zwischendurch für andere Transaktionen zu nutzen. Der Unterschied liegt in der untersten Hardwareschicht: Statt des Busses setzt SCI auf Ringe als Netztopologie, wobei in größeren Systemen mehrere Ringe zur Leistungssteigerung durch Switches gekoppelt werden können.
Die Übertragungsrate in den aktuell erhältlichen System beträgt - je nach Version - bis zu 4 Gigabit/s. Mit Hilfe von SCI kann man nicht nur dedizierte Parallelrechner bauen, die innerhalb eines geschlossenen Systems SCI einsetzen, sondern man kann auch gewöhnliche PCs oder Workstations mit PCI-SCI-Karten ausrüsten. Die SCI Karten erscheinen im Adreßraum des PCs mit einem relativ großen Speicherbereich (32 MB bis 2 Gigabyte), dieser Speicher ist aber auf der Karte nicht physikalisch vorhanden. Stattdessen erzeugen Zugriffe auf diesen Speicher über SCI Transaktionen Zugriffe auf den Speicher in einem anderen Rechner. Wie die Adressen umgesetzt werden, läßt sich über eine Adreßumsetzungstabelle auf der Karte steuern. Da die gesamte Abwicklung des Protokolls in Hardware stattfindet, sind solche entfernten Zugriffe sehr schnell, Schreibzugriffe benötigen weniger als drei Mikrosekunden. Bei der Bandbreite wird der PCI-Bus zum Engpaß, dieser kann zwar theoretisch 133 Mbyte/s übertragen, in der Praxis jedoch weniger. Wir haben zwischen zwei PentiumII Computern knapp 80 Mbyte/s Übertragungsrate gemessen. Dank der hohen Übertragungsrate auf dem Ring kann man auch bis zu acht Computer an einen Ring anschließen, ohne Engpässe zu befürchten.
Die Abwicklung des Protokolls in Hardware läßt eventuell vermuten, man benötige keine Software mehr, dem ist jedoch nicht so: Die einzelnen Zugriffe - bei denen es auch auf die hohe Geschwindigkeit ankommt - werden komplett von der Hardware abgewickelt, die gesamte Verwaltung gemeinsam genutzter Speicherbereiche hat jedoch in Software zu erfolgen. Für die SCI-Karte existieren zwei Treiberfamilien, eine vom Hersteller der Karte (Dolphin), eine von der Universität Oslo, die auch die Firma Scali einsetzt. Beide waren ursprünglich für Solaris und Windows NT entwickelt worden, inzwischen sind sie jedoch an der Universität Paderborn nach Linux portiert worden. Im Vergleich zu anderen Gerätetreibern ist die Komplexität erschreckend hoch: Der Treiber von der Universität Oslo besteht aus ca. 25000 Zeilen Code, der Dolphin-Treiber ist nahezu doppelt so groß, da er zusätzlich noch Maßnahmen zur Fehlertoleranz beinhaltet. Wie kommt es, daß die Treiber so kompliziert sind? Man kann es sich klar machen, wenn man die Aufgaben betrachtet, die sie zu erledigen haben: Sie müssen nicht nur lokale Speichersegmente verwalten, sondern auch die Verbindungen zu entfernten Segmenten abwickeln. Dazu müssen sich die Treiber auf verschiedenen Computern untereinander "absprechen". Zusätzlich kommen dann noch Sonderfunktionen hinzu, wie zum Beispiel die Möglichkeit, auf einen Interrupt zu warten, der von einem anderen Computer ausgelöst werden kann.
Der größte Aufwand liegt aber sicherlich in der Verwaltung der Adressen: Physikalische Adressen, entfernte Adressen sowie lokale virtuelle Adressen. Ein Problem war dabei die Notwendigkeit, größere physikalisch zusammenhängende Stücke zu verwalten. Linux kann in der Standardkonfiguration maximal 128 Kilobyte in einem Stück zur Verfügung stellen, nach längerer Laufzeit des Systems jedoch auch nur mit recht geringer Wahrscheinlichkeit (wegen der Fragmentierung des Speichers). Ein Ausweg aus dieser Situation bestand darin, beim Systemstart einen Teil des Speichers für SCI zu reservieren und diesen dann separat zu verwalten. (Diese Kernmodifikation ist als "Bigphysarea-Patch" auf der Arminius Webseite frei erhältlich, sie ist auch für Framegrabber-Treiber nützlich.) Neben der reinen Speicherverwaltung bietet der Treiber auch noch Synchronisationsoperationen an: So kann ein Prozeß auf einen Interrupt warten, der von einem anderen Rechner aus ausgelöst werden kann.
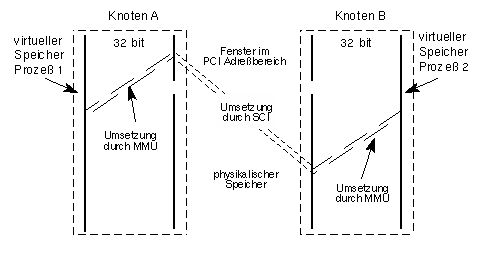
Es sind drei Adreßabbildungen notwendig, um ein auf Knoten B liegendes Segment sowohl auf Knoten A als auch auf Knoten B in Prozeßadressräumen einzublenden.
Auf der Basis aller dieser Dienste ist inzwischen auch ein Netzwerkinterface (SCIP - Sci-IP) entstanden, daß kürzere Latenz und höheren Durchsatz als Fast Ethernet bietet. Eine genauere Untersuchung steht noch aus, vermutlich ist es die leistungsfähigste Netzwerkanbindung, die man momentan für PCs unter Linux erhalten kann, so daß SCI auch in diesem Bereich eine interessante Alternative zu anderen Netzen sein kann. Auf der ganzen Welt verteilt stehen inzwischen mindestens zehn SCI Cluster, die Linux als Betriebssystem verwenden, der größte davon an der Universität Paderborn. Er besteht aus acht Doppelprozessormaschinen, sechs mit PentiumPro, zwei mit PentiumII. Der gesamte Cluster war dieses Jahr im Rahmen einer Gemeinschaftsaktion mit Scali und Siemens Nixdorf auf der Cebit zu sehen. Die Universität Paderborn plant momentan die Anschaffung eines wesentlich größeren SCI Clusters, der vermutlich auch unter Linux laufen wird. (Ein dritter Cluster mit 32 Knoten läuft momentan unter Solaris, soll jedoch später unter Windows NT laufen.) Der im Bild gezeigte schwarze Turm enthält die kompletten PCs, inklusive Gehäuse, um den Aufwand eines Umbaus in Spezialgehäuse zu vermeiden. An der Frontseite sind noch vier Leuchtdiodenstreifen angebracht, die die aktuelle Auslastung der einzelnen Knoten anzeigen. Sie werden über den Druckerport angesteuert.

Zusammenfassend kann man sagen, daß sich mit Linux als Betriebssystem viele Lösungen zur Erreichung hoher Leistungen konfigurieren lassen. Das preisliche Spektrum reicht dabei von kostenlosen Varianten (vorhandene, bereits vernetzte Computer) bis zu Speziallösungen wie SCI oder Myrinet, die schnell mehr als 100000,- DM kosten, dafür aber in anderen "Sphären schweben".
Netzquellen
- Scali: http://www.scali.com
- Dolphin: http://www.dolphinics.com
- ISS: http://www.iss-us.com
- Myricom: http://www.myri.com
- ParaStation (Universität Karlsruhe): http://wwwipd.ira.uka.de/ParaStation/
- PVM: http://www.epm.ornl.gov/pvm/
- MPI: http://www.mcs.anl.gov/mpi/index.html
- Beowulf (NASA): http://cesdis.gsfc.nasa.gov/beowulf/
- Arminius (Universität GH Paderborn): http://www.uni-paderborn.de/fachbereich/AG/heiss/arminius/index.html
- Max-Planck-Institut Sarbrücken: http://bigbrother.ag1.mpi-sb.mpg.de/